Sometimes it’s really challenging to come up with a relevant or interesting topic for a scheduled column. I’ve been doing this for a number of years, and one thing that I recognize is that sometimes the universe just hands you a topic, all gift-wrapped and ready to go. This is one of those times.
As I write this column, it’s July 19th. Last night, an update pushed out by CrowdStrike disabled hundreds of thousands of Windows devices around the world. Period. There will definitely be a lot of technical postmortems analyzing exactly what happened. What failed? How did the failure slip through QA? It’s much more interesting to talk about what you, as an individual, and your organization should do to prepare for the next outage like this. As noted cyber security author Nicole Perlroth said, “Although this is not a cyber attack itself, it’s a good preview for what a cyber attack might look like.” You wake up in the morning, and you don’t have internet access. You can’t buy gas at the gas station. You can’t buy a coffee at Starbucks. And when you get to the airport, your flight can’t leave.
In this case, the impact was worsened by two concurrent outages at Microsoft. One was an outage in the US Central region for Azure that took some core services offline. That led to availability problems with several Microsoft 365 services. So think about that for a second: Today we have two unrelated but widespread problems that affect individual devices across nearly every industry in most of the world, plus problems with cloud-based authentication and productivity services that many of the world’s businesses depend on. That is a fairly terrible combination. In this case, it was just bad luck that those outages happened near each other in time. But the next time, it might be the outcome of a deliberate effort by a threat actor, or by some broad natural disaster, or by another mistake delivered at scale by some infrastructure service you depend on.
I would be remiss if I did not mention the absolutely terrible job that most media outlets did on reporting this outage. Far too many of them got the Microsoft 365 outages mixed up with the problems caused by CrowdStrike or exaggerated or mislabeled the impact. In my first Practical Protection column, I recommended some trustworthy sources for this type of news, and if you’re not regularly checking them, now is a good time to start.
Protecting Your Organization
It’s hard to come up with any uniform recommendation that could protect you against every similar potential outage in the future. In this case, the problem occurred because a CrowdStrike driver got a bad update that rendered machines unbootable. If those machines had been protected by BitLocker, you needed the BitLocker recovery key to be able to boot the machine into safe mode. So the obvious protections are “Don’t allow bad updates” and “Keep copies of your BitLocker keys somewhere safe.” Even though those are obvious, it’s probably worth checking to see that you’re doing something along these lines.
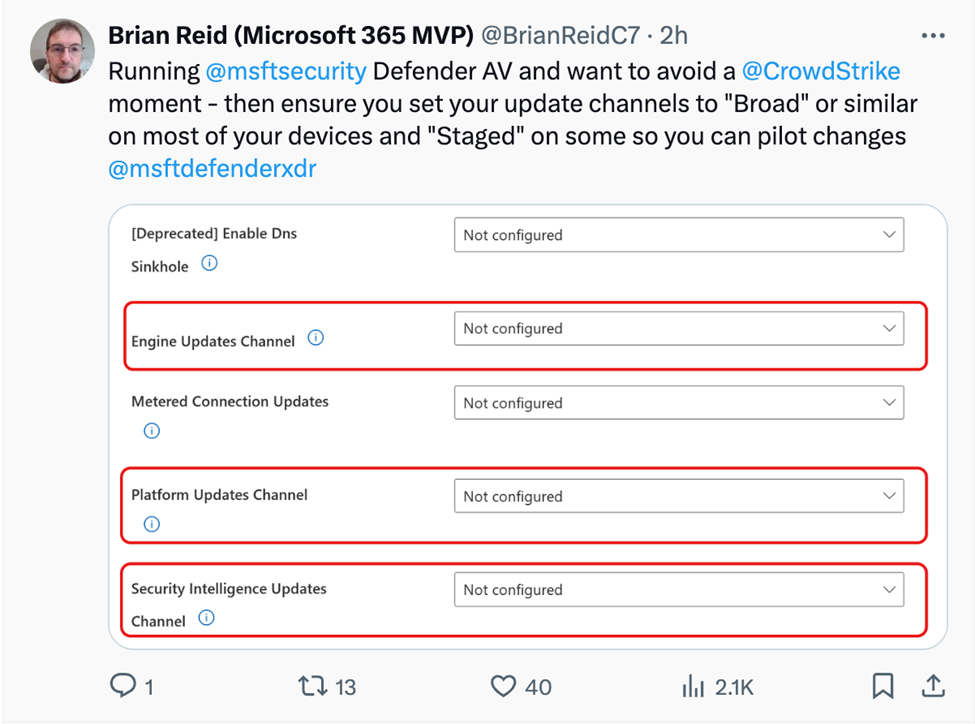
For updates, you can use the Windows and Office servicing tools to stagger updates so that you deliver new updates to a test fleet before allowing them to go global. For example, M365 MVP Brian Reid suggests staggering your update channel assignments as shown below if you’re using Microsoft Defender AV:
BitLocker keys are tricky. By default, they’re supposed to be backed up to Active Directory (for domain-joined devices) or Entra ID (for hybrid- or Entra-joined devices). That raises some questions—have you checked to see whether those keys are being stored properly? Do you know how to get them? Are there any critical services running on non-domain-joined machines where you need to keep the BitLocker printed out in a safe somewhere? Because these keys can be used to decrypt the corresponding devices, they (along with LAPS passwords) are security-sensitive themselves so you probably shouldn’t store or print them en masse, but your operational requirements may dictate otherwise.
Of course, no discussion about protecting the organization would be complete without mentioning disaster communications. Many of the organizations that were affected by the CrowdStrike outage found that they did not have a good way to communicate what was going on to their employees or to their customers, either because they couldn’t use Microsoft 365 or because they had no plan to determine how to answer Mattis’ three questions. You can imagine how many airline customers found out about flight delays or problems from watching inaccurate reports in the media. As I write this, right now most of the major airlines are at least able to update flight status on their own websites, but not all of them are able to communicate with customers, and many other organizations (including hospitals, manufacturers, and law enforcement and government agencies) aren’t able to either.

Protecting Individuals
If you’ve met me you probably noticed that I am generally a really optimistic person, so this list of recommendations may seem weird. I grew up in a hurricane-prone part of America, though, and a long career in IT has helped reinforce that early experience—so I know that optimism isn’t as useful as preparation. There are a few simple steps that you can take now to help cushion the impact of future outages on you and your family:
- Start by keeping some cash on hand. You don’t have to be a Rockefeller to be able to squirrel away a couple of hundred bucks so that you will have an emergency fund in case your credit card stops working at the gas pump. I
- Improve your discipline about keeping your vehicles fueled, whether you drive a gas, diesel, or electric vehicle. If you need to travel suddenly, it would stink to find that you don’t have enough fuel to get where you need to go.
- For the most important people in your personal and professional life, you should have multiple ways to contact them that don’t depend on cloud services. Even a simple handwritten list of phone numbers (ideally including landline numbers where available!) and addresses can be very valuable when you don’t have reliable Internet or cellphone access.
- Run some informal what-if or tabletop exercises with you and your family in mind. For example, you might ask “What would I do if I couldn’t contact my kids’ school because their phone system is down?”
The point of these steps isn’t to freak you out or turn you into a bunker-building super-prepper; it’s to help you consider possible scenarios, do a reasonable risk assessment, and mitigate, transfer, or eliminate the risks that you think are most significant… just like you do at work.
HIBGIA
A doctor I sometimes fly with taught me a valuable acronym: HIBGIA, which stands for “had it before, got it again.” That’s where we are with infrastructure outages and cyberattacks—this particular problem seems to mostly be resolved, and we may not have another similar problem for a while, but the odds are excellent that we will have one at some point. Some forethought and preparation now can save you a lot of trouble later.


