Exchange administrators like neatness. And one of the ways that we strive for neatness is by developing a system for organizing mailboxes among the available databases.
Popular mailbox organizing systems include:
- Grouping mailboxes by surname
- Grouping mailboxes by department
- Grouping mailboxes by type
In theory, creating a system for organizing mailboxes means we always have an answer for questions like:
- Where should I put this new mailbox?
- Where can I expect to find that one particular mailbox?
- When a database goes offline, who exactly will be impacted by it?
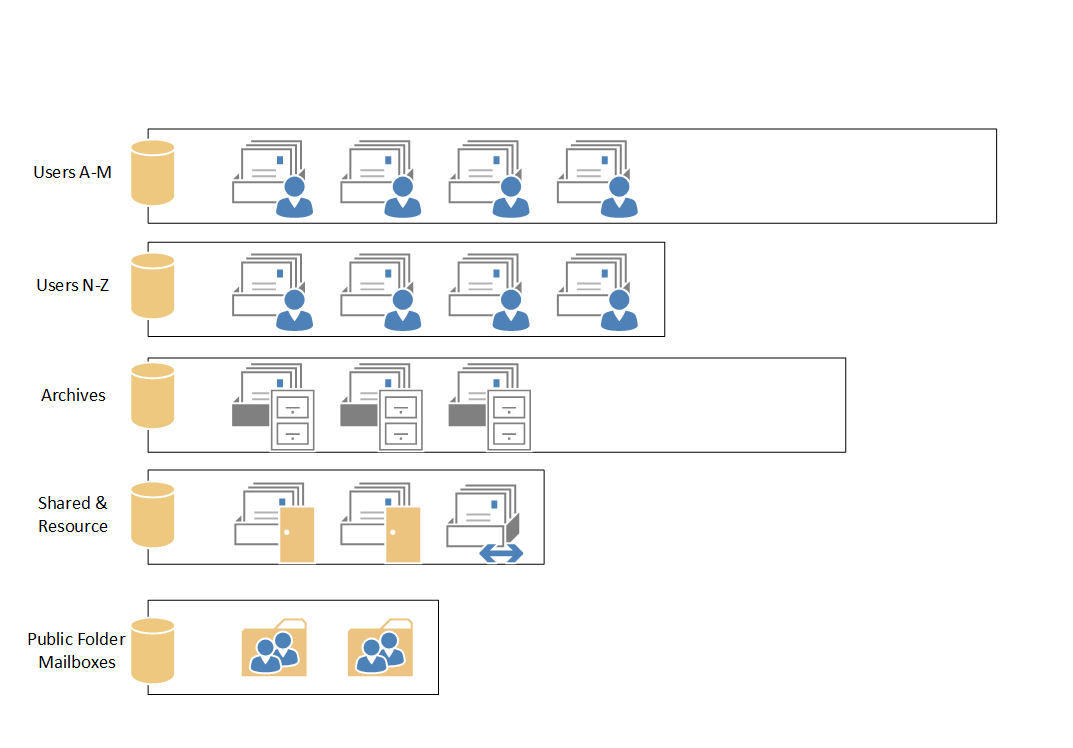
Let’s say that we come up with a plan to split mailboxes up as follows, with each of these groups getting their own database:
- Users A-M
- Users N-Z
- All archive mailboxes
- All shared/resource mailboxes
- All public folder mailboxes
Looks neat and tidy, but in the real world such systems start to fall apart very quickly. Database grow at inconsistent rates, have different I/O profiles due to different numbers of users, and when things start to get less neat and tidy you end up breaking your rules by shuffling a few mailboxes around to try and even things up again.
In comparison, a mailbox distribution for which the goal is consistency of performance and growth might end up with mailboxes distributed in a seemingly random way instead.

The thing is, what looks messier from an administrator’s perspective is usually better from a performance and capacity management perspective. And both of those things is more important than trying to create and adhere to a system of mailbox organization that only serves to create more work for yourself. Not only that, rules end up getting broken. Your neat separation of mailbox users by surname gets messed up pretty quickly when two people named Smith both turn out to be the biggest mailbox users in the environment, and one of them needs to be moved elsewhere.
Of course, all of that is not to say there are never reasons for specifying particular databases for a particular purpose. Organizations might choose to use a non-replicated database, separate their DAG, to host the mailboxes for departed users for a period of time before they are purged from the environment. Journal mailboxes are another candidate that can require a dedicated mailbox database. And having specific databases for users who are provided a certain level of mailbox storage quota is also an acceptable reason.
But generally speaking, my advice is to consider each mailbox database equally capable of hosting any mailbox in the organization, and focus more of your efforts on managing performance and capacity instead of strict rules about who goes where.



Thank you, Paul; that’s an excellent tip. In my organization, we took it a step further. We have a separate database for the Journal mailbox and another dedicated for Onboarding. All new mailboxes get created in the Onboard database and a script runs daily which determines the best place to locate the mailbox based on geographic location, DB user counts & DB whitespace. Setting up this process like this took the guesswork out of our user provisioning process and maintains even distributions of users and DB size across DAGs.
That’s a great idea. I don’t suppose you would be willing to share an example of the logic you guys use to determine the correct mailbox?
https://technet.microsoft.com/en-us/library/ff477621(v=exchg.150).aspx