In an Exchange Server 2013 organization where high availability is a requirement you need to consider both the Client Access and the Mailbox server roles.
Although a Database Availability Group can provide high availability for the databases hosted on the Mailbox servers, the Client Access server needs to be considered separately for HA.
In Exchange 2010 high availability for the Client Access server was achieved through the configuration of a CAS Array and some form of load balancing (hardware/virtual, or Windows NLB). Although the CAS Array no longer exists in Exchange 2013, and other architectural changes mean that load balancing can be approached in different ways, the basic concept of a single namespace for Outlook connectivity remains.
Here is a general demonstration of configuring high availability for Exchange 2013 Client Access servers.
To begin with, two Client Access servers have been deployed in a site. The servers are multi-role servers and are also members of the DAG that has been deployed. A third server is installed with only the Mailbox server role and is a member of the DAG as well.

A mailbox user connecting via Outlook 2013 is connected to server E15MB2, as shown here in the Outlook connection status dialog. There was no manual configuration required for this, it is just how Outlook autodiscovered the endpoint to connect to.
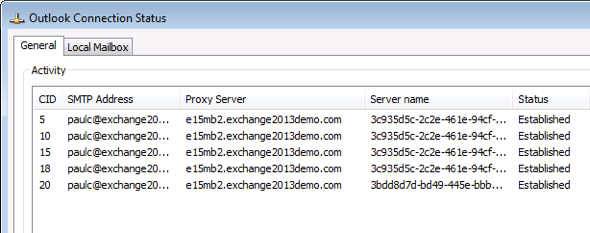
The mailbox databases are currently active on E15MB2.
[PS] C:\>Get-MailboxDatabase -status | select name,mounted,mountedonserver Name : Mailbox Database 1 Mounted : True MountedOnServer : E15MB2.exchange2013demo.com Name : Mailbox Database 2 Mounted : True MountedOnServer : E15MB2.exchange2013demo.com
The trouble begins when E15MB2 goes offline. The databases are able to failover to other DAG members and remain available.
[PS] C:\>Get-MailboxDatabase -status | select name,mounted,mountedonserver Name : Mailbox Database 1 Mounted : True MountedOnServer : E15MB1.exchange2013demo.com Name : Mailbox Database 2 Mounted : True MountedOnServer : E15MB3.exchange2013demo.com
However the mailbox user is no longer able to connect to E15MB2 and access their mailbox.
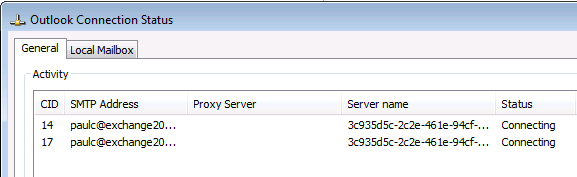
Eventually Outlook may autodiscover other available Client Access servers in the site and connect to one of them, but it is not an ideal user experience.
To improve this situation we need to look at the Outlook Anywhere configuration for the Client Access servers. If you’re not already familiar with Outlook Anywhere from previous versions of Exchange it is the service that provides RPC/MAPI connectivity for Outlook clients over HTTP or HTTPS. While this was typically only used for remote/external access in the past, architectural changes in Exchange 2013 mean that all Outlook connectivity is via HTTP/HTTPS even for internal clients.
At the moment each of the servers is configured with their own name as the internal host name for Outlook Anywhere, which is the default.
[PS] C:\>Get-ClientAccessServer | Get-OutlookAnywhere | select identity,*hostname Identity : E15MB1Rpc (Default Web Site) ExternalHostname : InternalHostname : e15mb1.exchange2013demo.com Identity : E15MB2Rpc (Default Web Site) ExternalHostname : InternalHostname : e15mb2.exchange2013demo.com
We can configure a single namespace for these instead of the unique server FQDN for each. Note that when configuring the InternalHostName you also need to set the InternalClientsRequireSSL option as well. To keep this example simple I am not requiring SSL for internal clients.
[PS] C:\>Get-OutlookAnywhere | Set-OutlookAnywhere -InternalHostname mail.exchange2013demo.com -InternalClientsRequireSsl $false
We also need to make sure that the DNS records exist for that namespace and resolve to the Client Access servers. With no load balancer available to me at this stage I am using DNS round robin, which is not as good as proper load balancing but will do the job for now.
PS C:\> Resolve-DnsName mail.exchange2013demo.com Name Type TTL Section IPAddress ---- ---- --- ------- --------- mail.exchange2013demo.com A 3600 Answer 192.168.0.187 mail.exchange2013demo.com A 3600 Answer 192.168.0.188
The change made with Set-OutlookAnywhere is not instantaneous. It takes about 15 minutes for the Client Access server to update with the new configuration. You’ll be able to tell it has taken effect when an Outlook autoconfiguration test returns the new value for Exchange HTTP.
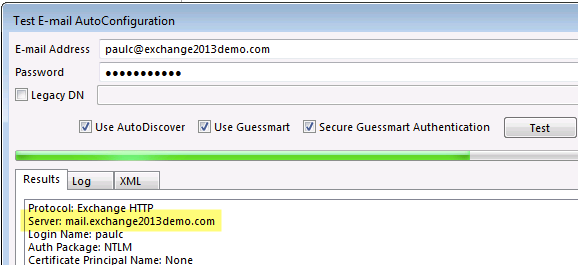
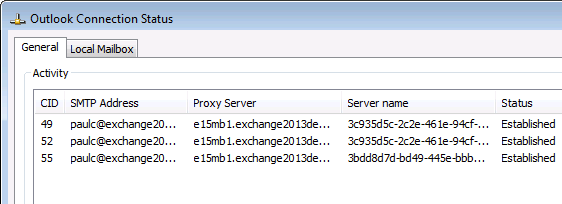
After waiting a while and then restarting Outlook the client is connecting to the newly configured namespace. I left this for about 30 minutes before restarting Outlook only because I wanted to test the result quickly. In the real world you could just let users restart Outlook in their own time (eg the next business day).
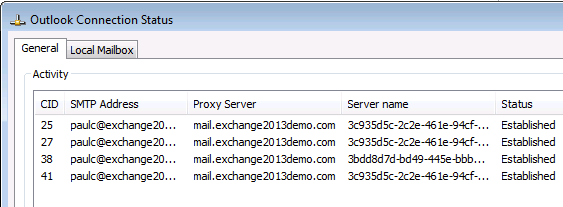
Netstat shows me that the client has resolved mail.exchange2013demo.com to 192.168.0.188 and Outlook is connecting to E15MB2 at the moment.
C:\>netstat -ano | findstr ":80" TCP 192.168.0.181:50967 192.168.0.188:80 ESTABLISHED 2272 TCP 192.168.0.181:50968 192.168.0.188:80 ESTABLISHED 2272 TCP 192.168.0.181:50979 192.168.0.188:80 ESTABLISHED 2272 TCP 192.168.0.181:50980 192.168.0.188:80 ESTABLISHED 2272
So to test high availability I shut down E15MB2 while observing the Outlook connection status dialog.
Without the aid of a load balancer the Outlook clients takes about 20 seconds to time out and then re-establish connectivity to the other IP address that mail.exchange2013demo.com resolves to. A much better user experience than before the Outlook Anywhere namespace was configured on the Client Access servers.
C:\>netstat -ano | findstr ":80" TCP 192.168.0.181:51010 192.168.0.187:80 ESTABLISHED 2272 TCP 192.168.0.181:51011 192.168.0.187:80 ESTABLISHED 2272 TCP 192.168.0.181:51012 192.168.0.187:80 ESTABLISHED 2272 TCP 192.168.0.181:51013 192.168.0.187:80 ESTABLISHED 2272
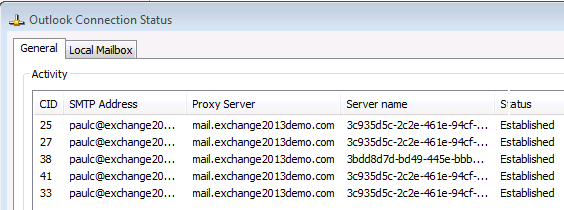
So there you have it, a basic demonstration of Exchange 2013 Client Access server high availability. In upcoming articles we’ll look further at load balancing options for Exchange 2013 CAS, as well as how to configure the external hostname and the SSL options for Outlook Anywhere.



HI Paul,
DAG config:
Create DNS entries like below and this should work:-
Mail.domain.com : – 192.168.80.25
Mail.domain.com : – 192.168.80.26
autodiscover.domain.com: – 192.168.80.25
autodiscover.domain.com: – 192.168.80.26
In the internal environment, it is ok to run but the WAN environment is problematic.
Ip WAN: 10.10.10.1, 10.10.10.2
2 nat: 10.10.10.1-> IP: 192.168.80.25 port 25, 443,80
2 nat: 10.10.10.2-> IP: 192.168.80.26 port 25, 443,80
But external NAT DNS public does not support load balance robin
Can you help me?
thanks
Hi Paul.
Thanks for the great Article. I am going to migrate from 2007 to 2013(I know it is too late). I have 4 server
1 MBX1 –Mailbox Role
2 MBX2- Mailbox Role
and configured as DAG
3) CAS1-CAS Role- with Private IP 192.168.10.20
4) Cas1- CAS Role- with Private IP 192.168.10.21
I have created the internal DNS record for mail.domain.com with 2 IP(192.168.10.20 and192.168.10.21) as you mentioned .I have public IP x.x.x. 41 to X.x.x.47.
How I will configure external DNS for both CAS.Is I need to configure the “mail.domain.com “ with 2 public IP ?
First point I will make is that the best practice is to use multi-role servers, instead of separating CAS and Mailbox roles like you have. If it’s not too late for you to rebuild your environment, it would be beneficial to do so.
For your question, normally a load balancer is used. If you don’t have a load balancer, and you want to use DNS RR instead, you will need two public IPs.
Thanks for your reply. I have an existing exchange 2007 with 600 mailbox. I installed the server role as I mentioned and migrated some mail box to new server. DAG also in place. So is it possible or required to go back?
Hello Paul ,
Thanks for your reply .
In some of the blogs i have found we may get those details by using the below mentioned URL’s ? Does Microsoft explains anything about the given URL’s ?
Please replace with your namespace when you are testing these URL’s in your environment.
https://nithya.test.com/mapi/nspi
https://nithya.test.com/mapi/emsmdb
https://nithya.test.com/mapi/emsmdb/?showdebug=yes
Reference link : http://www.msftexchange.org/mapi-over-http/
Hello Paul ,
Thanks for your reply .
Additionally in some of the blogs i have found we may get those details by using the below mentioned URL’s ? Does Microsoft explains anything about the given URL’s in any of official blogs ?
Please replace with your namespace.
https://nithya.test.com/mapi/nspi
https://nithya.test.com/mapi/emsmdb
https://nithya.test.com/mapi/emsmdb/?showdebug=yes
Reference link : http://www.msftexchange.org/mapi-over-http/
Hello Paul ,
Thanks for your reply .
Yes correct , I can search for the IIS logs but here the problem is i am having around 156 exchange servers and it is very difficult to parse the logs in all the servers while troubleshooting any issues , So how should i identify to which servers my load balancer is assigning the connections when i open my outlook ?
So to track that server name details – i will open outlook in my machine and simultaneously on the other end i will execute the netstat command against all of my exchange servers by filtering my machine ip address and port no 443 . If my understanding is wrong for my requirement then please share your views and thoughts to find out the name of the servers to which the LB has is assigning the connections when the user has opened the outlook.
I would still look at the IIS logs. Running netstat on 156 servers isn’t going to be useful, in my opinion. IIS logs can be quickly parsed using tools like Logparser or Logparser Studio, or custom scripts. If that’s too slow for you, invest in a log monitoring tool.
Hello Paul ,
Thanks a lot for spending your value time on this query .Yes i agree, At the end outlook user will get connected to the server which holds the user mailbox.
Environment Descsription : In my environment i am using MAPI over HTTP as the protocol and all of my exchange servers are attached to the HW load balancer .So first my outlook client will connect to LB and from there outlook connections will get proxied to the exchange server which holds my user mailbox.
But here i would like to find out what are all the servers which is participating in proxying the outlook connections to the exchange server which holds my mailbox ?
i have derived the below mentioned command .To find the exchange servers which is participating in proxying
$track = Get-ExchangeServer -Identity “EX*” | Select-Object -ExpandProperty name
$track | foreach {Write-host $_ ; Invoke-Command -ComputerName $_ -ScriptBlock {NETSTAT.EXE -a -n -o | findstr “136.13.170.246” | findstr “:443”}}
Note : 136.13.170.246 is My machines IP address.
Was the above mentioned is the correct way to achieve my requirement or you have any other recommended ways to check my requirement ?
The load balancer will send traffic to any of the servers in your load balancing pool. The load balancer has no knowledge of where your mailbox lives. It is only aware of servers. The server that receives the traffic on its frontend (Client Access) services will proxy the connection to wherever the mailbox is active. This is the basic architecture of Exchange and you can read more details about it on TechNet.
I don’t think that Netstat command is going to tell you anything. If you want to see where users have been connecting via the load balancer, look at your IIS logs on each Exchange server. That will show the HTTPS connections with usernames and other details.
Hello Paul ,
Thanks for your reply .It seems i have not explained you clearly .Let me correct my question.
In exchange 2010 we had used get-logonstatistics command to find out the list of servers on where a particular user session was established.
In exchange 2013 it is deprecated .Can you please tell me what is the best way to get this details ?
I’m still not understanding your need. Users get proxied to the mailbox server that hosts the active database copy for their mailbox. So they are connected wherever their mailbox is active at that time.
Continuation …..
Note : I have given the ip address of my system and the port number to list out the currently established connections from outlook to my exchange servers.On the output i could see my outlook has established around five connections with different exchange servers over port no 443 and then from the output i tried to find out the name of the process by using the PID value (which is 4) for the established connections but it shows just the process name as SYSTEM and no other informations.
One weird behavior what i have noticed is , the output doesn’t show the name of the exchange server which holds my mailbox .Other than that it is connecting and listing other exchange servers with PID value as 4 and the process name as SYSTEM .
Questions :
why netstat has not listed the name of the exchange server which holds my mailbox ?
Netstat is showing the process ID as 4 for other connected exchange servers but when i try to do a tasklist against that PID it shows the process name as SYSTEM ? I would like to know for which type of service connection my outlook was connected to those exchange servers ?
If you’re seeing Exchange server names (their real names) in the Outlook connection status dialog then that suggests to me that you have not configured your client namespaces correctly.
Download the ExchangeAnalyzer.com tool and run it to see whether it detects any namespace configuration problems.
Continuation …..
Issue : i would like to discuss with you about the netstat results and also the reason i would like to have deep dig is because this kind of requirements are mandatory for the environment which contains large amount of servers.
Here is the command which i have created to track all the outlook connections currently established with the exchange servers .
$track = Get-ExchangeServer -Identity “EX*” | Select-Object -ExpandProperty name
$track | foreach {Write-host $_ ; Invoke-Command -ComputerName $_ -ScriptBlock {NETSTAT.EXE -a -n -o | findstr “19.238.185.237” | findstr “:443”}}
Hello Paul ,
Environment Description : I need your support on this query .In my environment i am using MAPI over HTTP as the protocol and all of my exchange servers are attached to the HW load balancer .So first my outlook will connect to LB and from there connection will go to anyone of the exchange server .
Hi!
With Exchange 2010, I tried site resilience, with only 2 servers CAS/MBX. It works fine, even if Outlook must be restarted because “Outlook must be restarted because of configuration change”.
With Exchange 2013, I reproduce this. Using DNS RR cause latency (each Exchange can be CAS proxy..). I used different internal names. I don’t know why, but it does not work anymore. It’s strange to see that autodiscover (showed in the hidden XML file in user profile) know the new server, but Outlook can not reconnect!
I’ve 2 remarks:
– Do you think MAPI/HTTP changed something? MAPI “hide” the issue when a server is off
– Windows Server 2016 DNS Policy with geo-location could be very interesting for Exchange. Isn’t it?
Happy new year!
Hello Paul,
I have 2 mailservers and they are both CAS and DAG member. I use DNS RR, it works fine but my question is Send and receive connectors. If main server goes down, what should I do to send emails to external contacts?
Is it enough to add second server to Source Server section in Mail flow>send connectors> Default>Scoping? Or create another one? What should I do for failover? Or do you have any other advise?
Thank you very much in advance.
Kind regards,
Izac
Hi @paul,
first of all i am really thankful that you have made the migration guide.I have basically Followed your Migration guide from exchange 2010 to Exchange 2013 and this guide has helped me so much with understanding the concept about the exchange.
but now i am in small problem with me Setup.
I have 2 exchange server 2013 and one Exchange 2010 Server as CAS server. I have enabled the outlook anywhere setting as well and all the configuration looks good to me,
Get-OutlookAnywhere | select ServerName,InternalClientAuthenticationMethod,IISAuthenticationMethods,InternalHostname,ExternalHostname,InternalClientsRequireSsl
ServerName : SVV-EX2010-01
InternalClientAuthenticationMethod : Ntlm
IISAuthenticationMethods : {Basic, Ntlm}
InternalHostname : mail.domain.de
ExternalHostname : mail.domain.com
InternalClientsRequireSsl : True
ServerName : SVV-EX2013-01
InternalClientAuthenticationMethod : Ntlm
IISAuthenticationMethods : {Basic, Ntlm}
InternalHostname : imail.ruptly.de
ExternalHostname : mail.domain.com
InternalClientsRequireSsl : True
ServerName : SVV-EX2013-02
InternalClientAuthenticationMethod : Ntlm
IISAuthenticationMethods : {Basic, Ntlm}
InternalHostname : mail.domain.de
ExternalHostname : mail.domain.com
InternalClientsRequireSsl : True
I have also A records in my DNS server for both Exchange 2013 server with single namespace.
Everything seems to be Working except sometime delay in connectivity with the Outlook.
it happens that sometime my Outlooks Connect so fastly without any delay and sometime it takes time more than 30-40 seconds to connect with server’s. can you please suggest me something about it, how can i resolve this problem.
thank you so much
Your Exchange 2013 servers have different internal hostnames for Outlook Anywhere, so that is probably what is causing the issues.
Yes Paul , Thats how it was configured in the past with exchange 2010 setup. we have two domain internal and external. so i had to use the diffrenet internal and external Host name.
Can you please share some idea about it.
thanks
I don’t know your environment or the technical/business decisions you’ve made, but it’s unusual for two Exchange 2013 servers in the same site to have different Outlook Anywhere hostnames configured. Whatever internal and external hostnames you need to use, both servers should have the same configuration.
hey Paul,
This was mistake in the Typing , i actually have the same URL COnfigured on the both Server’s but i have diffrenent external and internal URL’s
For EG:
Internal: imail.domain.com
External: mail.domain.de
thanks
The client might be trying to connect to one of the hostnames, then timing out and connecting to the other one instead. That would explain a delay. But you’ll only be able to tell that by running network capture with a tool like Fiddler or Wireshark to watch the traffic.
Hi Folks,
Slight Struggle on the track…
Version – Exchange server 2013
Issue – Unable to use NLB cluster name (contoso.com’>mail.contoso.com) for autodiscover
I have a test environment called contoso.com, I have installed two Client Access servers (EX1 – CAS1, EX2 – CAS2).
CAS1 – 10.0.0.10 ex1.contoso.com
CAS2 – 10.0.0.20 ex2.contoso.com
NLB Virtual IP – 10.0.0.100 mail.contoso.com
I have added two CAS servers into NLB server, now I can access my mailbox through mail.contoso.com in owa, Suppose if I configure my outlook in my domain client, it should configure automatically for my mailbox through autodiscover service. Now my question is whether the client outlook(autodiscover) will try to reach ex1.contoso.com or ex2.contoso.com or mail.contoso.com ? If ex1,ex2.cotoso.com means how can I change the address to mail.cotoso.com ?
NLB isn’t really suitable for Exchange 2013 so it’s not worth learning. You’re better off deploying 2x multi-role Exchange servers and setting up a virtual load balancer like a Kemp, you’ll learn a lot more in terms of real world scenarios.
As for your Autodiscover question, the Autodiscover requests will go wherever your Autodiscover namespace (SCP) resolves to in DNS. If that’s the load balanced VIP, then it’s up to the load balancer to direct that traffic to one of the Exchange servers.
Paul,
I’m wondering about a mixed 2010 / 2013 environment.
I have two physical Exchange 2010 servers running in a DAG, MBS and CAA configuration and 1 virtual 2010 server running MBS only. Last year, we went through the exercise of changing from private FQDNs to public FQDN (i.e.: mail.domainname.com) on the CA servers (thanks TONS for your help with that), and we have the target CA namespace in a DNS Round Robin.
I’m planning to deploy two new virtual Exchange 2013 servers into the environment, and migrate mailboxes to new databases there. (Not deploying 2016 because the 2010 servers aren’t patched high enough, and are old and very twitchy, like me – I want to get *off* them.)
Assuming I configure the new servers properly to use the same namespace of mail.domainname.com for CA, can I just add those server IPs to the DNS Round Robin? Or would that cause any headaches?
During coexistence, the 2013 servers “front end” the 2010 servers. So yes, use the same namespace. But first, make sure your CAS array namespace is not the same as the Outlook Anywhere namespace. They should be different (CAS Array namespace should be unique and not externally resolvable). Once you checked that, yes deploy the 2013 servers with the same namespaces. You can then cutover the namespaces to the 2013 servers.
Dear Paul
I have 800 user, over 400 user is using outlook 2007 + outlook anywhere connecting to exchange 2010 with DAG and install different roles in different computer (VM). i want to upgrade to exchange 2013 with DAG. for the CAS, any suggestion?
I don’t understand your question.
Thanks so much for these detailed steps. We have this exact problem (lack of 2013 “cas array”) and followed these instructions (it took about an hour for the change to the outlook anywhere internal address to show up in test auto config, in case anyone else has the same experience). Once the change took effect however, Outlook could not connect.
I am wondering what port/s everyone else is allowing though on their load balancer for this (we went the LB option since it is available to us).
We allowed TCP 443 based on this MS article but perhaps more is needed?: https://blogs.technet.microsoft.com/exchange/2014/03/05/load-balancing-in-exchange-2013/
443 is the required port. If you suspect the load balancer might be an issue, point your namespaces in DNS directly at one Exchange servers to the load balancer is not used. If the problem goes away, then it’s likely the load balancer config is the issue.
Note also if you’re making DNS changes, lower the TTL to a value of 5 of fewer minutes (even down to 1 minute is good if you’re testing changes). You can also recycle the Autodiscover app pool in IIS on the Exchange servers to remove any cached info there.
Hey thanks very much for the help! Wish I had thought of setting the DNS to an Exchange server at the time.
We had the chance to reattempt this again over the weekend and used DNS round robin using the Exchange server IPs instead of the load balancer to see if the result was better– and it worked perfectly. We will probably stick with this solution for now as it provides us what we need, but we have the load balancer option up our sleeve should we decide to try and get that working in the future–so thanks for confirming port 443 is correct 🙂
Hi Paul,
My DAG and CAS HA is really working good after applying above solution. Now I am planning to perform CU update. Do I just need to follow you CU update article posted by you for DAG in my situation or do I also need to temporarily remove public DNS A record for one of the mail server while update is performed on the respective mail server?
If you want to be sure no clients will try to connect to the server that you’re updating, then yes remove that DNS record at the start of your maintenance.
The only confusion I have with CU update article is it says first start with “internet facing CAS server” but in the case of DNS round robin both are internet facing and outlook anywhere uses common certified FQDN. How to figure out which one is internet facing server. Should I consider first server that was installed before DAG and DNS round robin setup as internet facing server?
An internet-facing server is any server handling external client traffic. If there’s multiple servers behind a load balancer, then you’ve got multiple internet-facing servers. You can update them in any order. Remove one from your load balancing (or DNS RR), update it, add it back in, repeat with the next one.
Hello,
when i run test e-mail autoconfiguration i get this result:
Protocol: Exchange RPC
Server: d38a73x8-ec….@mydomain.com
should be like this or?
Also when i try to add or create profile on outlook i get:
“The action cannot be completed. The connection to Microsoft Exchange is unaviable. Outlook must be online or connected to complete this action”
and i have to go to More Settings>connection>outlook anywhere>exchange proxy settings and enter the URL
after that the name of the server changes to numbers and letters
Please advise
Thanks…. I figured out the problem with second server which did not have front end services and edge sync services running. Though test-servichealth showed status as true.
So internal DNS round robin was trying to take to passive when active was down but due to status of services it was still trying to back to active copy.
Internal services are working when one server is up with witness. Now I will have to add second public IP on external DNS, public to private one to one NAT to point to second exchange server on firewall and add that interface to securence inbound mail filter to achieve redundancy.
The only thing I am suspicious about is 1to1 NAT on firewall, how it will prioritize one over the other. May be I will have to test with both 1to1 NAT and SNAT and see which one works better
On this article you have used –
Get-OutlookAnywhere | Set-OutlookAnywhere -InternalHostname mail.exchange2013demo.com -InternalClientsRequireSsl $false
But in my case, I already had active server using correct FQDN “mail.fabcomlive.com” and it was showing SSL as TRUE.
I only ran the same command on second server Get-OutlookAnywhere -identity second server | Set-OutlookAnywhere -InternalHostname mail.exchange2013demo.com -InternalClientsRequireSsl $True
Is that the reason I am having connection issues from Outlook 2011 from MAC when both servers are on?
Outlook 2011 for Mac uses Exchange Web Services (EWS) to connect, not Outlook Anywhere.
If you want high availability, you need to configure it for all namespaces and services.
test-servicehealth and replication is good –
Role : Mailbox Server Role
RequiredServicesRunning : True
ServicesRunning : {IISAdmin, MSExchangeADTopology, MSExchangeDelivery, MSExchangeIS,
MSExchangeMailboxAssistants, MSExchangeRepl, MSExchangeRPC, MSExchangeServiceHost,
MSExchangeSubmission, MSExchangeThrottling, MSExchangeTransportLogSearch, W3Svc, WinRM}
ServicesNotRunning : {}
Role : Client Access Server Role
RequiredServicesRunning : True
ServicesRunning : {IISAdmin, MSExchangeADTopology, MSExchangeMailboxReplication, MSExchangeRPC,
MSExchangeServiceHost, W3Svc, WinRM}
ServicesNotRunning : {}
Role : Unified Messaging Server Role
RequiredServicesRunning : True
ServicesRunning : {IISAdmin, MSExchangeADTopology, MSExchangeServiceHost, MSExchangeUM, W3Svc, WinRM}
ServicesNotRunning : {}
Role : Hub Transport Server Role
RequiredServicesRunning : True
ServicesRunning : {IISAdmin, MSExchangeADTopology, MSExchangeEdgeSync, MSExchangeServiceHost,
MSExchangeTransport, MSExchangeTransportLogSearch, W3Svc, WinRM}
ServicesNotRunning : {}
My active server was running mail.company.com name on all services except for mapi but my passive server was using dag-servername for FQDN name on services like web, activesync, AutoD. To keep it in sync with active server I exported and imported same SSL certificate from primary server and change connection name for all services to mail.company.com on Sunday.
Today, when I came to work I noticed that connection with Outlook 2011 on MAC were having issue although windows version and activesync was working. Unless the MAC version was using MAPI connection, which I have not changed. I shut down the passive server and the connection is working.
My goal was to test that mail.company.com works internally on all clients, once it is figured out I was planning to change NAT and external DNS to get round robin method of HA on existing DAG with two server featuring all server roles.
I have also added second A record on internal DNS zone for mail.company.com for internal round robin.
To get MAC client working have to keep passive server down for entire day during production hour and work later
Thanks for this it, really helped me set up my testlab.
For the live deployment we are going to be using the Kemp load balancer. So have configured this into my lab but whenever i try to access Outlook i get the prompt for username and password. it just sticks there and refuses to let me in.
Any ideas how i unpick this and put it back to the original names?
i have tried Set-OutlookAnywhere -Identity “************Rpc (Default Web Site)” but i just get the command completed successfully but no settings of ************ have been modified.
thanks
lee
Finally moving from 2007 to 2013 (wish it was 2016 at this point but I have been sitting on 2013 and do not have SA). We are a small company with 130 users. I am toying with making Exchange more available. Am I right in thinking that the way to do SSL across the CAS/MBX server is to use a SAN certificate? Seems pretty straight forward. What else do I need to consider that you didn’t cover?
Without knowing your current topology I can’t say. But it sounds like you’ve deployed separate CAS and MBX servers, which is not recommended.
I recommend this ebook if you’re planning a HA deployment:
https://www.practical365.com/ebooks/deploying-managing-exchange-server-2013-high-availability/
I have not deployed it yet and each Exchange 2013 box would be a CAS and Mailbox server. I will look at the book. Does it cover HA like this article or it is more geared for load balancers and all that. I am going for middle ground on the expenditures and like the approach you took in this article using round robin and such.
DNS RR and load balancing are both discussed in the eBook.
More to the point, a HA solution involves a lot more considerations than what your original question asked. So it would be a good idea to get across the whole solution, or you risk deploying something that is no more resilient than a single server.
Thank you for taking the time to reply. I downloaded the book the other day and begun reading.
Like every other article on this site, this is again a very straight forward and informative article. Thanks for helping us.
Paul, great work on the article, really informative.
We are currently looking to move away from a standalone exchange 2013 installation and into a 2013 DAG setup, I understand from your article that this is achieved internally via DNS round robin, however, how does this work externally?
What we would have is externally a name say mail.mycompany.com this points to a single IP address externally on our router, this is then NAT’d and the IP address of the external IP points on port 25 and 443 to an internal IP however, with DNS round robin internally there isn’t one IP I can point this at, what is the recommendation here?
Thank You
Joe
DNS RR is just one way of doing it. It works fine, but a load balancer is more effective, and solves the problem you’re looking at with just one public IP being NATed to a single internal IP.
One DAG per site (node dag’s)
Then each site should have its own namespace.
Hi Paul,
I seem to have a strange problem and could do with some advise.
I have the below Exchange 2013 setup
Site1:
Exh01 – CAS, Mailbox – 192.1.x.x
Exh02 – CAS, Mailbox – 192.1.x.x
DAG01
Client IP’s – 10.1.x.x
Site2:
Exh03 – CAS, Mailbox – 10.2.x.x
Exh04 – CAS, Mailbox – 10.2.x.x
DAG02
Client IP’s – 192.2.x.x
OWA – DNS Round Robin to all 4 servers
Autodiscover – DNS Round Robin to all 4 servers
Now users in Site1 are sometimes connecting to servers in Site2, and vica versa.
As you noticed the IP ranges are a mess up.
I have DNS servers setup for round robin and Netmask ordering, but because of the ip ranges, netmask ordering isn’t really helping.
Any suggestion?
Thanks in advance
If Site1 and Site2 host different DAGs then the Client Access namespaces for those sites should be different.
Hi Paul,
Is there any other way to get this to work with DNS, as I am trying to avoid have multiple namespaces to manage for OWA, Autodiscover, etc
Thanks
Do you have one DAG in each site, or a single DAG stretched across both sites?
Pingback: Load Balancing Exchange 2013 (CAS) with clustered (Zen) Load Balancers | A random blog from a sysadmin
Pingback: Avoiding Server Names in SSL Certificates for Exchange Server 2013
Thanks, Will ActiveSync connect/redirect to online servers if some servers are off line?
Or will have to set a Short TTL and take server out of RR if they are down?
We are a small site with 3 servers, don’t really have the $$ to but Load balancers.
Thanks.
ActiveSync will handle DNS RR just fine in my experience. A short TTL is recommended for any DNS RR anyway. And if the outage is expected to be a long one you can always drop the inactive IPs out of the DNS RR.
So how would this work for external access, for OWA, outlook and ActiveSync the same way?
Have 3 nat rules and 3 A records for mail.xxx.com? I’m assuming outlook on the outside would work the same but what about OWA or activesync?
Thanks we are using a cisco asa if it matters?
3 IP addresses, 3 NAT rules, and 3 A records would work.
If you don’t have enough IPs for that, a single IP/NAT/A record will also work if you can either load balance the connection using the firewall itself, or NAT to a load balancer that can do it.
Hi Paul Cunningham.
i have question about Exchange Server 2013 Client Access Server High Availability
if i have 4 sites, the primary site in Egypt, and all other sites in other country, the 3 sites have Additional Domain And have Mail Box 2013 and Create DAG.
i want when the primary site down, all other sites can send and receive internally..
how i can do that ?
Hi Paul,
We are in the process of migrating from Exchange 2010 to Exchange 2013. 16 of the 20 sites are running on Exchange 2013, so only 4 to go.
As the CAS Array has been “dropped” in Exchange 2013, can we safely remove the clientaccessarray objects? Of are they still used in some way?
I could not quite figure out that answer from your, yet another, great article.
In forward thanks!
They aren’t needed after the mailboxes are moved to 2013.
Paul, thanks for you reply and guidance. Can you please tell me the exact forum where I can post my question so that I can get some help on this?
Hi Paul,
First of all, thanks a lot for this wonderful information.
The problem I am facing is with creating a MAPI profile with Exchange 2013 CAS server.
I have deployed 2 servers with client access roles and 2 servers with Mailbox roles. The AD/DNS server is deployed on a separate server. I have tried using both NLB & DNS round robin technique for load balancing between the CAS servers. the load balancing is working fine in both the cases. Initially I faced the issue in creating the outlook profile and everytime while checking the name, it used to say “The name could not be resolved”. But after going through your article about the exchange certificate, I have replaced the self signed certificate installed on the 2 servers having client access roles with the CA certificate . After that, the outlook profile gets created successfully with server name given as “Mailbox GUID @ domain”.
But even after doing all the configuration and installing the appropriate certificate on client servers, I am unable to create the MAPI profile with the exchange 2013 CAS server. Everytime, while creating the profile, it shows an error as “The name could not be resolved. Network settings are preventing connection to Microsoft exchange server”. I have tried to resolve this issue by doing various configurations but still I am not able to solve this issue . Now at this moment I am not getting any clue as to how to resolve this issue and what specific configuration is missing at my end . Note that the MAPI CDO is installed on a separate windows machine (not having outlook installed) and is in the same domain as the exchange 2013 cas servers.
So I request you to please guide me and help in understanding the cause of this problem so that the MAPI profile gets created successfully with the CAS 2013.
Thanks once again,
Akshat.
I’m confused. You say that the Outlook profile is created successfully, then you say you can’t create the profile. Which is it?
Hi Paul,
Sorry for the confusion. Let me detail more about my setup.
At our site, we are working on a voicemail application which interacts with the exchange server 2013 . Now, when a mailbox user (created on our application) receives a voicemail then an email notification for the new voicemail received is sent to the users on their email address configured. All this interaction that occurs between my application and exchange server is via IMAP protocol.
But IMAP can only support upto limited number of users.
So the new requirement in our application to support large number of users is to make use of MAPI protocol. Now in order to achieve it, we are using one application known as MAPI gateway, which resides between my voicemail application and the exchange server CAS 2013. My voicemail application first sends the request to the MAPI gateway via IMAP , which later interacts with the CAS server via MAPI protocol.
Now, on MAPI gateway side configuration, en exchange superuser account is needed to create profile. This will take care of all the mailboxes residing on my application.
So what I did was I have created one superuser on CAS server and created its email account. Next, on the MAPI gateway side which is installed separately on Windows machine, I am giving the same super user account, but everytime while checking the name, it is showing me error as “The name could not be resolved. Network settings are preventing connection to the exchange server.”
Other fields which are needed to configure on MAPI gateway application are:
exchange server domain – I have given domain of the CAS servers (MAPI gateway application is also in the same domain).
exchange server host: I have given the host name which I have configured for Outlook anywhere for the 2 CAS servers (say mail.ex2k13.com). The host file entry is created in DNS which resolved to the NLB IP.
Superuser credentials
Exchange server GUID : Given the GUID for the superuser created on exchange.
Furthermore, from the same machine on which MAPI gateway application is installed, the NLB host name is pingable and OWA/ECP is also working. I have also tried it with the DNS round robin load balancing but everytime it shows an error message and the profile does not get created.
Please help me to resolve this issue as I am not getting any solution to proceed further.
Thanks once again for your support and great work
Developer questions like this are not really my area of expertise. I can see on TechNet/MSDN there is specific versions of MAPI CDO needed for Exchange 2013. Other than that I suggest you ask in the TechNet forums where there is a dedicated Exchange development forum.
Hi Paul, Thanks for the valuable information. The query I am having is related to configuring Outlook profile with Exchange server in CAS mode. In my lab setup, the Mailbox and Client access roles are running on different servers . As u said I have followed all the above steps and made the DNS entry. Now when I autodiscover through Outlook then it shows connection as successful.
The problem arises when I try to configure the email account in Outlook. While configuring it, when I give the server name and the mailbox name, then during check name it shows an error as “The name could not be resolved. The outlook is not online or is disconnected”. The machine in which outlook is running is in the same domain as that of the exchange server and have a dns entry for it. Can you please guide me what may be issue and what steps I need to follow to configure outlook with exchange 2013 in CAS mode? Also please tell me what I have to write as server name while creating the email account in Outlook?
Thanks in advance.
hi Paul,
Once again thanks for your great work!!
Have you ever explained about HA solution for Exchange 2013 CAS server when it comes to multiple internet facing sites with DAG stretched across these sites?
For external OA connectivity, I guess i’ll have to setup 2 separate external URL’s for external outlook anywhere and the redirection to be enabled on site.
For internal OA connectivity, i guess my client will directly connect with one of the CAS server by DNS round robin as it has the list of CAS servers in the network from configuration XML.
Sure. We cover some of the more complex HA scenarios in our ebook about High Availability:
https://www.practical365.com/ebooks/deploying-managing-exchange-server-2013-high-availability/
Very Easy to follow and well written walk-through.
My question is in regards to roles configured on the servers. I have a single data center scenario with 3 servers to handle Exchange Services for 350 mailboxes. 1 CAS, 1 MBX and 1 MBX/CAS. With the DNS round robin configured for Servers 1 and 3 (the two with the CAS role installed) am I missing how this would not be a suitable HA setup? I should be able to take out any one of the three servers for maintenance/updates without affecting service to my users; correct? This is a slightly different setup than the given scenario for the article; but I don’t think that scenario given is also the end all setup which prompts my question.
For clarification, the mailbox servers are configured in a DAG which uses a separate DC as the witness server. The DAG has been operational for over a month and appears to be working properly allowing users to connect to either server depending on which server is active.
Thanks,
Dan
Multi-role servers are recommended.
With 3 servers you could deploy 3x multi-role servers and get a robust HA deployment where CAS is load balanced (or DNS RR) across 3 servers, as well as having all 3 server be DAG members and have 3x copies of each database.
Thanks Paul, I understand.
Obviously, this makes things robust for client access and mailbox availability. What about mail delivery from the outside world? I can add multiple MX records to deliver email, but I would need to ensure that each server with that was designated to receive email had a Front End Transport Receive Connector; correct? Or more specifically; which of the roles allows for emails to be received by the server, does the MBX role receive the email or does the CAS role receive the email?
Thanks,
Dan
The CAS role receives inbound mail from the internet, and it is pre-configured with connectors suitable for that task.
Hi Paul,
We have a very curious situation. Our environment is mixed Exchange 2010/2013 environment. All clients connect through on of the 2013 CAS servers. Current setup:
CAS13-01
CAS13-02
MBX13-01
MBX13-02
These mbx servers are part of DAG02
CAS10-01
CAS10-02
MBX10-01
MBX10-02
These mbx server are part DAG01
We are using webmail.ourcompany.com as namespace using a split dns setup.
We have configured the CAS13 servers to use DNS RR. On both cas servers all the vDirs are configured to use webmail.ourcompain.com as internal and external url. Outlook anywhere is configured on both CAS servers to use webmail.ourcompany.com. We also use Lync 2013 and the integration with EX13 is giving us headaches, this seems to be an EWS issue.
The strange thing is the following,
A) if I explicitly point webmail.ourcompany.com to use EX13-01 (using the hosts file) and I open https://webmail.ourcompany.com/EWS/Exchange.asmx in Internet Explorer, I get the expected “You have created a service.” page.
B) If I explicitly point webmail.ourcompany.com to EX13-02 (using the hosts file), I get a login prompt which keeps popping up despite filling in the right credentials, so I don’t get to the “You have created a service.” page.
C) Then if i point webmail2.ourcompany.com to EX13-02 (using the hosts file), and I open https://webmail2.ourcompany.com/EWS/Exchange.asmx in IE, I do get the “You have created a service.” page.
So to me it seems like using the same FQDN for both CAS13 servers doesn’t work and/or produces unexpected behavior (to my knowledge at least). Or at least EWS doesn’t like this at all.
This causes the Lync exchange/outlook integration to malfunction; it keeps giving login prompts in the Lync client when connecting through EX13-02.
We have installed EX13-02 completely from scratch, but this didn’t fix the issue. What am I missing here? Or is this an unsupported configuration?
In forward thanks.
Regards,
Erik
I think we found the problem, it has to do with the authentication provider order on the EWS virtual directory. By default the order is Negotiate, NTLM. According to this article http://lyncuc.blogspot.nl/2013/01/lync-and-exchange-web-services-ews-and.html NTLM should be first. After changing the provider order to NTLM,Negotiate our problem described above disappeared.
So it seems like then when you “load” balance Exchange 2013 CAS servers using DNS Round Robin, you have to change the authentication provider order on the EWS virtual directory.
Regards,
Erik
I have seen repeated logon prompts and EWS issues similar to what you’re describing, and the IIS auth provider order was also the cause of those.
I don’t think load balancing or DNS RR is a contributing factor. I have seen this in single server environments as well.
Hi Paul,
Thanks for your reply. It appears that a CU, we found out as we just installed CU8, will restore the provider order to the original configuration “negotiate, NTLM”. This pointed me to SPN’s. In our configuration it appeared that EX13-01 had the following spn “http/webmail.contoso.com” this spn was not linked to EX13-02. As soon as we removed the spn “http/webmail.contoso.com” the problem disappeared as well.
I agree that DNS round robin isn’t a contributing factor. But as you have seen this in single server environment as well, I am not sure what the actual culprit is or the specific SPN or the provider order or maybe both…
regards,
Erik
Hi Paul,
Thanks to you, my DNS round robin works well. But I have one problem, one of my CAS was down last week, outlooks started to ask for password. This server is also DAG member, DNS and DC.
I have also another DC/DNS(AD integrated) and one DAG/CAS servers. What do you think can be reason?
THank you very much in advance.
Your first problem is that using a Domain Controller as a DAG member is unsupported.
If Outlook is asking for a password it likely means that you have either:
– not configured your namespaces the same on both servers
– not configured the same/correct SSL certificate on both servers
– not configured your virtual directories and Outlook Anywhere configuration the same on both servers
Thank you very much for prompt answer. When I first started to work for this company, they had just one server for DC,mail etc. I added 1 more exchange and another DC.
I checked the certificates and virtual directories, checked DNS records for namespaces and they are identical.
I think I have problem with DNS configuration, what do you think? Or can be a delay on DNS round roubin? For example 5 minutes later, this password won`t be problem anymore?
Thanks again.
No I doubt it was due to DNS. It’s also possible the server that was down was hosting the PF mailbox or something that the Outlook client was trying to connect to.
In my scenario we install exchange 2013 sp1 on physical server on both side DC and DR. we found outlook client connectivity issue with user mailbox guid. Then we check autodiscover xml address in internet explorer(https://CAS fqdn/autodiscover/autodiscover.xml) it can’t ask me credential then i remove proxy / allow proxy bypass in internet explorer.After that it discover my exchange autodiscover and search mailbox guid in outlook client configuration.
ohoo this very struggle to find out.
For the DNS RR set externally that means that clients could connect to outlook anywhere using either site correct? We have a Primary and DR site and don’t necessarily want clients connecting to the DR site for outlook anywhere. I guess I can set a weight on the DNS record to assist with that.
As far as autodiscover goes, I am not using a Load balancer do you recommend using two different Autodiscover URI’s one going to the primary site and one going to the failover site I know you mentioned a blurb about that possibly causing issues can you elaborate on that please.
For the Autodiscover do you recommend keeping a single name space and using DNS RR externally and Internally with Split DNS, or do you recommend having like autodiscover.company.com and failover.company.com with the Primary site using the autodiscover.company.com URI and the DR site using failover.company.com. Thanks I couldnt edit my post so sorry for adding this on.
Yes, DNS RR will send clients to both. If you want to avoid that you could either not use DNS RR, and just manually adjust DNS records in a DR situation. Or you could use a DNS solution like Amazon’s Route 53 that will use health checks to failover to the DR site only when the primary site is not available.
For the external autodiscover CNAME I would just do the same solution as you’re doing for the rest of your namespaces (eg DNS RR, or Route 53, or other).
For internal Autodiscover SCPs I prefer a simpler approach with one namespace everywhere, unless it is a large/complex environment with many Exchange sites, or with network latency that requires a more controlled Autodiscover experience for different sites (eg someone out on a remote site with poor WAN connectivity and its own local Exchange server should preferably query that local server for Autodiscover). But Autodiscover itself is generally a lightweight service so if the network is good then don’t overcomplicate it with multiple namespaces.
Dear Paul,
A great article, thanks!
Could you give me a piece of advice how to correctly set records in external DNS to receive and sent mail?
Two servers Exh1 и Exch2, both of them CAS and MailBox:
Exch1.test.com – 192.168.50.2
Exch2.test.com – 192.168.50.3
DAG – 192.168.50.4
Mail.test.com – CAS Load Balancing according to your article, i.e. 192.168.50.2 and 192.168.50.3.
Everything works fine inside a company.
But:
External MX –record in external DNS – 1.2.3.4, for example.
There is NAT in external DNS available that translates 1.2.3.4. to ONLY internal IP 192.168.50.10 for email to be accepted and sent.
Is it possible to configure both CAS servers in internal DNS by creating additional any record to refer to this only IP 192.168.50.10 to receive and sent external mail?
For example, I create one more A record in internal DNS mail.test.com that refers to 192.168.50.10 and create MX record that refers to 192.168.50.10 also.
In that case, mail.test.com keeps three records:
Mail.test.com A 192.168.50.2
Mail.test.com A 192.168.50.3
Mail.test.com A 192.168.50.10
Does this configuration working to successfully receive and send mail if I have NAT from external IP to ONLY internal IP?
If not, how to correctly publish CAS Load Balanced Servers in external DNS? Which and how many records do I need to create to solve this matter?
Thank you!
Thanks for your advice! Apparently, it looks ok (I verified in a testing environment) and hence I consider if it can be deployed in production. However, I also look for a professional advice for supporting. If it is not advised, I will certainly abandon this approach!
Thanks very much Paul !!
If only two servers (both shared CAS and Mailbox servers role), can we use DAG IP as a failover solution instead of using Round Robin??
Checked that I can use https://dag_ip/owa and https://dag_ip/ecp to admin the Exchange.
No.
Would you pls tell in what situation setting DAG IP as the DNS record fail (provided that CAS and mailbox role are co-exist)?
When the active mailbox server is down, the other passive one can take up the DAG IP (and role) to serve the OWA, ECP and ActiveSync services.
Thanks!
The DAG IP is not a client access endpoint. It is not designed to act as a client access endpoint. Trying to use it as a client access endpoint is not the correct way to deploy the product. I am not going to try and predict every possible way that it might cause a failure. I’m sure if you continue trying to use it as a client access endpoint you’ll discover a lot of interesting ways that it will fail. My advice to you is to design and deploy your Exchange services the correct and supported way.
Pingback: 4 weeks to MCSE : Messaging – 70-341 (4/5) | David Bérubé's blog
Hi Paul,
I followed everything in this tuto as you explained above, but I am facing a problem, when I put my “Server A” and “Server B” down, and let only the “Server C” up, My outlook lose connection even if I can reach mail.domain.local and the status appear as “Connecting” and only come back if I put “Server A” and “Server B” up. The database is fine, but I think that is something of how Outlook reach the working server, I don’t know :/
do you have any idea of how can I solve this problem?
Sorry for my poor english
What are you using to load balance the traffic? Perhaps it is not doing health checks properly and is still sending traffic to the servers that are down.
Hi Paul,
I have 2 CAS and 2 DAG Members, when occurs a failover Outlook reconnect very slow, (3minutes), what im missing???
Thanks
Perhaps the databases are taking that long to mount on the other DAG member? Look at your event logs for the failover events and work out a timeline of what is happening on the servers, and go from there.
Hi
I have 2 CAS, in different subnets/locations. Both are bound by split-DNS ext/int. Lets say server.domain.com. Outlook anyware has the name set both internally and externally.
DNS is Round Robin.
I have Outlook 2010/2013 clients that don not move to an active DAG when one have failed. Or it takes forever. Restart Outlook/PC help. They are in Cached-Mode, if set to non Cached-mode they work better. Is there anyway to improve this?
Appreciate any ideas!
Best Regards
Robban
Hi Paul,
First of all thank you for exploring your inputs & outputs to all.
As per your document refer to i had configured 2 CAS SERVERS with High Availability through DNS Round robin in our environment.
Now i’m trying to configure Outlook Anywhere through single name space in my client machine its thrown Error: A Connection was interupted E0000x00 Etc…
But I can able to configure outlook anywhere through single CAS Server Name in my client machine its working fine.
what mistake i made can you guide me please…
You should not need to manually configure anything in Outlook, it should all be automatically configured by Autodiscover.
we have two exchange server 2013 with DAG (installed both Mailbox and CAS) CAS round robin is not working (outlook client is saying trying to connect while DB mounted server down and DB mounted with another server )
is SSL certificate must for internal?
can i create CAS array in this scenario?
There is no CAS array for Exchange 2013. You need to either use DNS RR or a load balancer.
DNS RR works fine but that doesn’t mean it won’t break if there’s something wrong. I recommend keeping both your servers online and doing some testing. Take out one of the DNS entries for the CAS namespace and make sure all the clients work fine when they are hitting just that one CAS. Test DB switchovers and make sure it continues to work. Repeat the process by changing the DNS entry to point to just the other CAS.
My guess is you will find something wrong with one of the CAS configs.
Yes you should configure an SSL certificate.
I have 7 servers in the environment. 3 are CAS servers 2 are MBX servers and 2 are both which are in different countries. I want the 3 CAS servers to answer to the single namespace and the other 2 combo servers to answer to their own names. how do I do that
I got it working by setting the internal name on just the 3 Cas server
All you need to do is configure different namespaces on the virtual directories for the servers in each site. So the servers in Site A might use mail.na.contoso.com and the servers in Site B might use mail.eu.contoso.com.
Hi Paul,
when using dns round robin method, is it necessary to lower the TTL to a single second?
Thanks.
No, absolutely not.
Hi Paul,
thanks. should we leave it at default ttl levels?
worried about local dns cache on the clients machine which would still be pointing to an affected server, should the server be unavailable/fault.
thanks in advance.
If you’re using DNS round robin the client will stop trying after about 20 seconds and will use the other IP addresses that DNS returns for that name.
But yes, you should lower the TTL for maintenance and outage scenarios where you want to remove the record from DNS. 5 minutes is a reasonable TTL for these, if you ask me.
I have a 2013 DAG all Virtual. 2 in Main Site and 1 in Branch site. When the primary server goes down clients can no longer connect, but if I do a manual DAG failover and the main server stays up all mail continues to flow.
I am having difficulty pinning down the issue. Any guidance would be appreciated.
Hi Paul,
What about the virtual directories on first and second CAS? Should they keep the server name or should we change them?
Thanks
Pingback: Dr. Vincent Malfitano
Hi Paul,
If you use DNS RR for CAS HA, how do you think you can updgrade CAS server during maintenance?
I don’t find any way for seing connected users per Exchange 2013 CAS Server, and I don’t find how to place CAS server on maintenance mode.
The only way what I see is to temporarily delete DNS record, and monitor with Netstat active connexions…
What do you think about it?
Thanks,
Yes you can take the record out of DNS while you do the maintenance.
Hi,
When I install second CAS, users getting certificate window with yes and no option (I have certificates from external source). How can I solve certificate and virtual directories? Could you please advise?
Configure the namespaces on the new CAS server to match the other one in the site, and also export/import the SSL certificate to the new server.
https://www.practical365.com/exchange-2013-ssl-certificate-export-import/
If using DNS Round Robin, you would need to configure this on your external DNS zone as well and create a static NAT mapping for every CAS server to be made available externally as well, right?
forgot to check the notify me of follow up comments via email block 😛
Correct. If you want to use DNS RR for HA for external client connections, yes.
Pingback: How to Install Exchange Server 2013
hy Paul,
i have an exchange 2010 DAG with 2 exchange 2010 servers , the two servers have the MBD and CAS roles.
server1: 192.168.0.1
server2: 192.168.0.2
DAG: 192.168.0.3
when i dismount the database on server1, the clients stil connecting to their mailboxes but when i shutdown the server1 a blockage is hapened and no connection to the mailboxes.
why !!!
Clients connect to the Client Access server role, not the Mailbox server role. A DAG only provides HA for the Mailbox server role. If you want Client Access HA as well for Exchange 2010 you need to configure a CAS Array and use some form of load balancing to make it highly available.
https://www.practical365.com/exchange-server-2010-cas-array/
yes Paul, I know this, but why the second server in the DAG blocks (plantage in frensh) and the copie of the mailbox database on the second server do not passe to the MOUNTED status when I shutdown the first server ?
thank you.
Sounds like there’s a problem with your DAG. When you’re doing planned maintenance you should not just shut down the server. You should do a planned switchover of the databases first.
If that switchover fails, then you’ve got a DAG health issue that you need to investigate further.
If the switchover is successful then something else is causing failovers to fail. The event log will tell you more information about this. It could be a problem with the other database copies, it could be a quorum problem, it could be lots of things really.
thank you Paul
Thanks mate.
I’ll check that out and report back.
However, one thing I haven’t really got is this from your reply: “…that each NAT to one of your Exchange servers?”.
Could you elaborate please?
Cheers.
NAT = Network Address Translation. You might also refer to is as port forwarding or simply forwarding. Basically it is your firewall saying “When I get a HTTPS connection on this public IP address I should forward it to this internal server”.
We have two Exchange 2013 (both CAS and Mailbox) one is active another passive (replicate). I’ve followed your guide here, and I do maintain connectivity when I turn off the main Exchange and able to send emails. However, I am unable to receive external emails when connect to the second server.
Checked DNS everything looks fine.
In addition, on the passive server I am unable to use ActiveSync, it only works on the main server.
Could it be host/firewall issue?
Thanks mate.
Are you load balancing the SMTP/HTTPS traffic coming in from the internet to both Exchange servers?
No load balancing, just DNS round robin.
So you’ve got two A records in your public DNS zone, resolving to two different public IP addresses on your firewall, that each NAT to one of your Exchange servers?
If that is the case then I’d say check that the DNS and NATing for the second one (the one the doesn’t work for you) is set up correctly.
Has anyone tested this with the new MAPI over HTTP client connectivity introduced in exchange 2013 SP1 and outlook 2013 SP1? Does it improve the reconnection times of outlook?
Pingback: Exchange 2010 to 2013 Migration – Cut Over Namespaces
Thanks Paul
You mentioned above
Remember NLB only detects if an entire server is down. If just one service (like OWA) is failing then it won’t know and will keep directing traffic to it. And because the client only has one IP to connect to (the NLB VIP) it can’t decide to try another IP instead, as it can with DNS RR.
Is it possible if service fails on one host in NLB for CAS we remove the host with failed service and NLB serve clients with other available hosts. Will this overcome the NLB drawback or may be I am not clear
Don’t use NLB. I’m not going to get into tricks and tips to make NLB a better option. Just don’t use it.
But in DNS RR Incase one CAS goes down clients will still point to the failed CAS IP. If I remove the record too from DNS Server the clients might use local DNS cache instead of querying DNS server and keep resolving to failed CAS IP. May be this would not give efficient CAS failover. How to eliminate this thing in HA using DNS RR?
You can lower the TTL on those DNS records to minimise the risk of clients using cached records.
Hi Paul,
I have 2 sites with 2 Exch 2013 servers at each, all 4 in a single DAG. I have redundant load balancers at each site. In DNS, should I have two IP addresses configured RR for the DAG and should those addresses be the two virtual IP addresses of the load balancers?
Hi, Paul.
Thank you for your article. But it doesn’t work for me ((. Maybe you can help me and tell what I’m doing wrong.
I configured 4 VM’s – 2 domain controllers and 2 Exchange Server 2013 – all with Windows 2012 R2.
I created two “host A” records in DNS with the name “exchange.msc.loc”, pointing to each Exchange Server, and autodiscover alias, pointing to exchange.msc.loc. I also used the command “Get-OutlookAnywhere | Set-OutlookAnywhere -InternalHostname exchange.msc.loc -InternalClientsRequireSsl $false” and it was succesfull – I see “exchange.msc.loc” in Outlook autoconfiguration test.
I also created DAG and included both exchange servers in it.
Then I tried to test high availability and shut down first exchange server. And as you wrote it takes about 20-30 seconds for outlook to time out and then start reestablishing connectivity to the other IP address that exchange.msc.loc resolves to. I see communication with second exchange server in netstat and whireshark. But outlook shows me that there is now connection and it is still trying to reestablish it. I also see in whireshark that they communicate with each other using ssl packets. And many errors appears in windows application log on client (approximately one in 50 seconds) during this attempts. Here are the errors:
Rpc call (EcDoConnectEx) on transport (ncacn_ip_tcp) to server “15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru” failed with error code – 6ba, after waiting – 0 мс; eeInfo – Block (0), Error = 6ba, Version = 1, GeneratingComponent = 2, DetectionLocation = 1f5, Flags = 0, Params = 4, [Param (0) Type = eeptUnicodeString, Value = ncacn_ip_tcp], [Param (1) Type = eeptUnicodeString, Value = 15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru], [Param (2) Type = eeptLongVal, Value = a4f1db00], [Param (3) Type = eeptLongVal, Value = 6ba], Block (1), Error = 6ba, Version = 1, GeneratingComponent = 12,
DetectionLocation = 5a2, Flags = 0, Params = 1, [Param (0) Type = eeptUnicodeString, Value = 15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru], Block (2), Error = 6ba, Version = 1, GeneratingComponent = 12, DetectionLocation = 142, Flags = 0, Params = 0, Block (3), Error = 2afb, Version = 1, GeneratingComponent = 12, DetectionLocation = 140, Flags = 0, Params = 1, [Param (0) Type = eeptUnicodeString, Value = 15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru].
Rpc call (EcDoConnectEx) on transport (ncacn_http) to server “15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru” failed with error code – 6ba, after waiting – 47547 мс; eeInfo – Block (0), Error = 6ba, Version = 1, GeneratingComponent = 2, DetectionLocation = 6ae, Flags = 0, Params = 1, [Param (0) Type = eeptLongVal, Value = 0], Block (1), Error = 6ba, Version = 1, GeneratingComponent = e, DetectionLocation = 576, Flags = 0, Params = 2, [Param (0) Type = eeptLongVal, Value = 4], [Param (1) Type = eeptLongVal, Value = 6ba], Block (2), Error = 6ba, Version = 1, GeneratingComponent = d, DetectionLocation = 58e, Flags = 0, Params = 1, [Param (0) Type = eeptLongVal, Value = 1f7], Block (3), Error = 1f7, Version = 1, GeneratingComponent = d, DetectionLocation = 589, Flags = 0, Params = 1, [Param (0) Type = eeptUnicodeString, Value = Service Unavailable].
Rpc call (NspiBind) on transport (ncacn_http) to server “15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru” failed with error code – 6ba, after waiting – 47547 мс; eeInfo – Block (0), Error = 6ba, Version = 1, GeneratingComponent = 2, DetectionLocation = 6ae, Flags = 0, Params = 1, [Param (0) Type = eeptLongVal, Value = 0], Block (1), Error = 6ba, Version = 1, GeneratingComponent = e, DetectionLocation = 576, Flags = 0, Params = 2, [Param (0) Type = eeptLongVal, Value = 4], [Param (1) Type = eeptLongVal, Value = 6ba], Block (2), Error = 6ba, Version = 1, GeneratingComponent = d, DetectionLocation = 58e, Flags = 0, Params = 1, [Param (0) Type = eeptLongVal, Value = 1f7], Block (3), Error = 1f7, Version = 1, GeneratingComponent = d, DetectionLocation = 589, Flags = 0, Params = 1, [Param (0) Type = eeptUnicodeString, Value = Service Unavailable].
Rpc call (NspiBind) on transport (ncacn_ip_tcp) to server “15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru” failed with error code – 6ba, after waiting – 0 мс; eeInfo – Block (0), Error = 6ba, Version = 1, GeneratingComponent = 2, DetectionLocation = 1f5, Flags = 0, Params = 4, [Param (0) Type = eeptUnicodeString, Value = ncacn_ip_tcp], [Param (1) Type = eeptUnicodeString, Value = 15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru],[Param (2) Type = eeptLongVal, Value = f5cc5a18], [Param (3) Type = eeptLongVal, Value = 6ba], Block (1), Error = 6ba, Version = 1, GeneratingComponent = 12,
DetectionLocation = 5a2, Flags = 0, Params = 1, [Param (0) Type = eeptUnicodeString, Value = 15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru], Block (2), Error = 6ba, Version = 1, GeneratingComponent = 12, DetectionLocation = 142, Flags = 0, Params = 0, Block (3), Error = 2afb, Version = 1, GeneratingComponent = 12, DetectionLocation = 140, Flags = 0, Params = 1, [Param (0) Type = eeptUnicodeString, Value = 15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru].
Rpc call (RfrGetNewDSA) on transport (ncacn_ip_tcp) to server “15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru” failed with error code – 6ba, after waiting – 0 мс; eeInfo – Block (0), Error = 6ba, Version = 1, GeneratingComponent = 2, DetectionLocation = 1f5, Flags = 0, Params = 4, [Param (0) Type = eeptUnicodeString, Value = ncacn_ip_tcp], [Param (1) Type = eeptUnicodeString, Value = 15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru], [Param (2) Type = eeptLongVal, Value = 1544f5e0], [Param (3) Type = eeptLongVal, Value = 6ba], Block (1), Error = 6ba, Version = 1, GeneratingComponent = 12,
DetectionLocation = 5a2, Flags = 0, Params = 1, [Param (0) Type = eeptUnicodeString, Value = 15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru], Block (2), Error = 6ba, Version = 1, GeneratingComponent = 12, DetectionLocation = 142, Flags = 0, Params = 0, Block (3), Error = 2afb, Version = 1, GeneratingComponent = 12, DetectionLocation = 140, Flags = 0, Params = 1, [Param (0) Type = eeptUnicodeString, Value = 15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru].
Rpc call (RfrGetNewDSA) on transport (ncacn_http) to server “15895ba6-b845-4a46-a142-d0e98ee4bd13@exchange.domain.ru” failed with error code – 6ba, after waiting – 47531 мс; eeInfo – Block (0), Error = 6ba, Version = 1, GeneratingComponent = 2, DetectionLocation = 6ae, Flags = 0, Params = 1, [Param (0) Type = eeptLongVal, Value = 0], Block (1), Error = 6ba, Version = 1, GeneratingComponent = e, DetectionLocation = 576, Flags = 0, Params = 2, [Param (0) Type = eeptLongVal, Value = 4], [Param (1) Type = eeptLongVal, Value = 6ba], Block (2), Error = 6ba, Version = 1, GeneratingComponent = d, DetectionLocation = 58e, Flags = 0, Params = 1, [Param (0) Type = eeptLongVal, Value = 1f7], Block (3), Error = 1f7, Version = 1, GeneratingComponent = d, DetectionLocation = 589, Flags = 0, Params = 1, [Param (0) Type = eeptUnicodeString, Value = Service Unavailable].
And I have very strange situation – after 5-40 minutes (it differs from case to case and I don’t understand on which it depends on) it reestablished connection and errors stopped appearing in log.
Then I installed SP1 for Exchange Server on both servers and now the situation became worse )). Now it doesn’t reestablish connection no after 5 or 40 minutes or several hours, so never. And errors continue appearing in log.
For one thing you need to provision an SSL cert to replace the self-signed cert.
https://www.practical365.com/exchange-server-2013-ssl-certificates/
Other than that, either your databases aren’t failing over properly when you shut down the server or something else is wrong at the CAS or MBX layer. But wireshark won’t help you with that, you need to look at server event logs and use Exchange tools to look at database status etc.
Sorry, got you mixed up with someone else (about the SSL cert bit, though you should check that anyway).
Hello Kamil,
I have the exact same problem, did you ever solved this issue?
Greetings,
Hi Paul – I cant *over!
Reading your article, and many others, everything I can think of has been configured but clients will not reconnect after the database moves either from Server A-B or B-A, can you think of anything which may cause the issue?
Full details here: http://social.technet.microsoft.com/Forums/en-US/3dbe744d-358f-4a33-82c8-143cb6bf2be5/unable-to-connect-to-outlook-after-over?forum=exchangesvravailabilityandisasterrecovery
Thanks
Don’t waste your time on this one, it is yet another bug with 2013: http://support.microsoft.com/kb/2928803
Hi Paul,
can u direct me to all your articles that explain the design of exchange 2013 with two exchange servers, two clientserver and mailbox server roles and DAG and also using F5 as load balancing for HA. We are in the intial stage of migrating to exchange 2013 from 2010, so i want to get the design right from the onset
I wrote a series of articles on Exchange 2013 DAGs starting here:
https://www.practical365.com/exchange-2013-boot-camp-special-offer/
Multi-role servers are the recommended best practice.
For F5 setup I recommend using F5’s guidance and/or their iApp for setting up the Exchange 2013 VS.
in EAC i have configured mail.domain.com as Internal/External Address for Outlook anywhere and Auth set to Negotiate for both CAS Servers.
AutodiscoverService internaluri set to https://mail.domain.com/autodiscover/autodiscover.xml and Auth set to Basic and Integrated for Autodiscover virtual directories of both CAS Servers.
when i try to publish only one of the CAS Servers for OA and Active Sync everything is ok. Problems starting to Appear when i want to implement Preauth and Stop Publishing Exchange Web Services without Pre Checks!
Hello Paul
Iam getting following message in almost users
The Microsoft Exchange Administrator has made a change that requires you quit and restart outlook
I have 2 Exchange 2013 configured with DAG with out any Load Balancer.
Could you please help me to find a solution for this
Thanks
Saju
Have you configured the Outlook Anywhere namespace for your CAS?
Hi Paul,
i have configured Exchange 2013 like this :
1 AD 2012 R2
2 Mialbox Servers Exchange 2013
2 CAS Servers Exchange 2013
1 Edge Server Exchange 2013
1 TMG 2010
now i have inbound and Outbound mails traversing our Service and even OWA works Perfectly Published Using Server Farms (Cas Servers Behind Published Rule). since i have confiured OWA Rule and Listener to Forms Based and Auth delegation to Basic Auth OWA is OK. but when i reuse the Listener with Forms Based to Publish OA and Active Sync there is Repeating Password Prompts on Outlook 2013. when i add OA and Active Sync Virtual Directory Paths to OWA Publishing Rule Exchange COnnectivity Analyzer completes Successfully but yet Outlook Prompts for Password.
i wanted to Use KCD to Delegate Authentication against Exchange Servers but seems KCD doesn’t work against Server Farms ! am i right ?
currently we don’t have the option to purchase a Load Balancer.
is there any walk through to fix it ?
for now i am thinking of Separating Autodiscover URL IP Address and Configure a Separate Listener. but this is a Security Concern to us
May You please Help ! Really how you managed this ?
Pingback: Exchange Server 2013 – Introducción a Client Access High Availability | nicolasgranatadotcom
We have two exchange server 2013 both mailbox and cas (Virtual Host Machine) after completed cas array we can’t connected mailbox by using outlook 2007/2010/2013
There is no CAS Array in Exchange 2013.
I just completed the Exchange Server 2013 Client Access Server High Availability that have to this page(round robin)
Then I’m confused by your mention of a CAS Array.
Hi Paul,
you only configured the Outlook Anywhere name to the new round robin name “mail. ..”. What about the internal URLs for OAB, WebServices and the AutodiscoverURI setting on the clientAccessServer?
Thanks in advance.
Marcel
Take a look at this:
https://www.practical365.com/avoiding-exchange-2013-server-names-ssl-certificates/
Hi Paul,
Thanks again for a great article.
I have followed and successfully configured two Multirole Ex2013 in one AD site and a third one in a different AD site. Everything works perfectly, but OWA.
I mean, while Outlook connects perfectly regardless the server and the site, when I try to login to OWA on the Site B (either via namespace or the server’s FQDN directly) I cannot authenticate and returns always “The user name or password you entered isn’t correct. Try entering it again”. OWA on Site A works just fine.
I feel I missed something here, using a separate Site (different subnet), but I can’t find anything around.
What do you think?
Thanks in advance!
A.
Hi Paul,
having 2 multirole Servers in this Scenario – how would you apply cumulative updates? We can’t update the CAS roles seperately as they are running on the same System as the Mailbox roles.
Thanks.
Marcel
“The first servers to be updated in a site are the Mailbox servers. The Client Access servers are updated second. If you have multi-role servers installed then both roles are updated at the same time anyway, and you should simply start with the internet-facing servers.”
Refer:
https://www.practical365.com/exchange-2013-installing-cumulative-updates/
Hi Paul,
thanks for your great articles.
I have a question regarding the relationship between CAS and Mailbox servers in general. In your scenario, we have 2 multirole servers. From my understanding CAS proxies Outlook connectiions to the mailbox role and Outlook is not directly connecting to the mailbox role.
If BOTH Multirole Systeme are ONLINE:
Is it possible that an Outlook Client is using E15MB1 as a CAS, when the user mailbox resides on E15MB2?
Or will Outlook automatically use the CAS of E15MB2, because the mailbox is hosted on the Mailbox role of this server?
Thanks
Marcel
The client connects to the Outlook Anywhere namespace by resolving it in DNS.
In the case of DNS round robin the client chooses a CAS IP to connect to without any regard for whether that CAS also happens to be the MBX server hosting the active database copy for their mailbox. The same applies via a load balanced IP, the load balancer uses whichever algorithm you choose (eg least connections, round robin) to distribute traffic with no awareness of where the mailbox happens to be active.
So it is entirely possible and normal that a client may be connecting to CAS on E15MB1 while the mailbox is active on MBX on E15MB2.
Thanks Paul. Makes it clear.
Hey Paul,
Here is my current project:
Exchange 2007 to Exchange 2013 migration
We have two(2) sites
Chicago (Installing CAS & MBX)
Milwaukee (Installing CAS & MBX)
I plan on having a DAG between sites. Both sites are also Internet facing. I would like to setup HA on the CAS role also and make this failover properly if we lose one of the sites. Taking your above article into account, can you provide any ideas on the HA configuration.
Thanks and love you BLOG.
If you don’t mind which site clients connect to then having the Outlook Anywhere FQDN resolving to both sites’ CAS is an approach to consider.
If you do mind which site they connect to then have the Outlook Anywhere FQDN resolve to just the primary site and manually update it if there is a DR situation.
Thanks, Paul, that’s what I figured.
Any ideas for providing redundancy for externally reaching OWA/Autodiscover/ActiveSync? We use EOP so I will populate it with both of the Internet facing sites external IP address for port 25 traffic, but that still leaves HTTPS traffic (OWA/AD/AS).
Hi Paul,
I have a similar situation to JP above and I could really do with your help!
We have 3 physical sites, site A, B & C, with sites A & B having a really fast low latency links between them, so from an AD point of view they are 1 site. Site C has links to both sites A & B, but the link is a lot slower and it is a separate AD site.
We have an exchange design with 3 servers (one located at each physical site) that will form a DAG spread over the 3 physical sites. Ideally we will separate the CAS and mailbox server roles out and have them controlled by a hardware load balancer, however we can have both roles on the same server if required.
What we want, is to prevent is a situation where an outlook client in site C connects to a CAS server in site A/B with the mail being hosted on a mailbox server in site C therefore traversing the network twice to get its mail.
From doing the Microsoft training course, my understanding is that in Exchange 2013, the CAS server only proxy’s the request on to the mailbox server and does not redirect the request to the CAS server in the site where the mailbox server resides.
I have seen a information online stating that a single namespace is the way to go as long as your site links/network bandwidth is good, but nothing to help with our scenario.
Have you/anyone else come across this situation and how did you get round it?
Thanks in advance 🙂
If you want clients in site C to connect to a CAS in site C, then use a CAS namespace for site C that resolves to the site C Client Access server(s), and set the RPCClientAccessServer for those databases to that CAS namespace, and host the active database copies for those users in that site.
Hi Paul,
Thanks for getting back to me.
My understanding was that the RPCClientAccessServer attribute is depreciated in Exchange 2013 and is no longer used after any migration to 2013 has been completed.
Is this the case? Or Are you saying we can use it?
Thanks
Darren
Sorry I was answering too many comments last night and didn’t read yours properly. For some reason I thought you had an Exchange 2010 scenario you were asking about.
You’re correct, that attribute is not relevant to us in Exchange 2013.
Geo-DNS is probably something you should look into.
Your scenario is a curious one. Why are you trying to run a DAG over bandwidth that you also say is too poor to handle client connections?
Also, in cached mode the clients don’t really need much bandwidth. Is it a genuine problem for you if they are connecting to out-of-site CAS?
A little late responding to the older question but the issue is still important. It seems that in truth the Exchange is smart enough to figure out where the active database is and connect user to the CAS in the site where the active mailbox is. That is if internalHostNames are set to each site accordingly, that is different for each site, the users are connecting to the CAS server in their corresponding site as long as their mailbox is in the database that is also active in ‘their’ site. However, if database is activated in another site the user is then rediretcted to the internalHostName of the CAS in another site. For that to work the AllowCrossSiteRPCClientAccess parameter should be set to ‘false’ (which it is by default). The problem starts when servers in ‘SiteA’ lost quorum and Site-To-Site connection is down. Then ‘SiteA’ database is activated in ‘SiteB’ but users can not connect to it since there is no network access to the CAS servers in ‘SiteB’. Then seems like DNS RR balancing of a single namespace pointing to public addresses of CAS of ‘Sites A and B’ would be an option.
I have been working and testing Exchange 2013 HA with DAGS while learning Windows 2012 Dynamic Clustering. One question I can’t seem to answer is what type of traffic goes over the DAG IP? In testing I can have the dag “off-line” yet the databases can still sync up.
So what type of traffic actually goes across this DAG IP? I know this IP is tied to a Computer Name of the Dag – but what does actually do?
If the “active” dag ip is online in the DR site, yet our active Exchange 2013 mailboxes our mounted in the primary site, what type of issues, (or traffic issues) does this cause?
The DAG IP is used to connect to the PAM (Primary Active Manager) of the DAG. An example is a Client Access server that needs to know where the active database copy is for a user’s mailbox. It asks the PAM for that info.
The DAG IP is not used for database replication or client connectivity.
Couple of questions:
1. In the article it says “when configuring the InternalHostName you also need to set the InternalClientsRequireSSL option as well”. But you did not and it all still works well. So “need” in this context means “must” or “can”? So if I dont set the …RequireSSL parameter (either for internal or external client) what would happen? Also, is setting this parameter equivalent to checking ‘require ssl’ box in IIS or its independent setting?
2. What about setting the RPCClientAccessServer paramter – is it still required or no longer? Its still present and has a value pointing by default to one of the CAS servers. But does it do anything (considering the stores now decoupled from CAS and all communications now HTTP based)?
3. And still the all important question – should we understand that now with new way of load balancing between two data centers (say, located one in MT and the other in CA) users with active mailboxes in CA may happen to connect to MT CAS to get to their CA mailbox and there is no way for them to know or control it?
4. And the last one – how many namespaces would need to be configured in the simple case like presented in the article? Would just two be enough – mail.exchange2013demo.com and autodiscover.exchange2013demo.com? (Same for two datacenters?)
Thanks
1) I did set that option in the example.
2) Not required for Exchange 2013.
3) Yes. Geo-load-balancing would be a way to avoid that if it is a concern. Obviously that carries some costs with it.
4) A single namespace is the minimum. You can read more about that here:
https://social.technet.microsoft.com/wiki/contents/articles/17880.single-global-namespace-support-in-exchange-2013.aspx
Also demonstrated here:
https://www.practical365.com/avoiding-exchange-2013-server-names-ssl-certificates/
I used autodiscover.* as well because some mobile devices will try to use that in the autodiscovery process.
Thanks, Paul.
1. I understood it as the ‘need to set the parameter to “true”‘. So if Im getting it right it means it can be either true or false but needs to be set to something, otherwise client will not connect. Intuitively one would think it should have some value by default.
2. Great. So its just another legacy parameter that MS sloppily left that does not do anything. One thing less to worry about.
3. Got it now. So thats the reason why we still might need geo-balancers. Otherwise Exchange would not figure out which way is better to connect client to the closest site. Its random (until something breaks).
4. Very useful links (both). Got it now. Though still autodiscover is a little confusing topic. In your article you are setting up single namespace for all services (including autodiscover) but then in the link to setting up Certificates you are saying:
“With all of the namespaces configured the next steps are:
Generate a Certificate Request for Exchange 2013 that only includes the minimum required names (in this case mail.exchange2013demo.com and autodiscover.exchange2013demo.com).”
Typo?
Or, after some thinking, maybe I am getting it after all – the minimum required names is a single name but then autodiscover most likely will not work (unless ‘domain only’ portion pointed to the same IP as all other services). To make sure it does work at least two names should be on certificate – single for all the services and another one for autodiscover.mydomain.com. In addition, the External autodiscover name is not configurable and need not to be configured, its assigned by Exchange itself. Only internal URL for autodiscover service needs to be setup manually.
And it is also my understanding that not only mobile devices but Outlook as well will try to use the autodiscovery link (otherwise, what else would it be using for autoconfiguration?).
Hopefully, I got it right now.
Thanks
1) When you are setting the internal URL you need to explicitly set the SSL option as well. Try running the command without that and you’ll see what I mean.
2) Calling it sloppy is a bit much. The attribute exists in the schema for objects of that type. What options do they have? Remove it and probably break legacy systems, or create a whole new object type and duplicate effort?
3) Exchange doesn’t figure anything out. The client looks up the namespace in DNS and resolves it to one or more IPs to connect to. It isn’t really up to Exchange to determine whether you should be connecting to Site A or Site B if they both have the same namespace.
4) You can run a single namespace for domain-joined clients that have the ability to look up the Autodiscover SCP in AD. Non-domain-joined clients (like mobile devices) can’t do that, and instead fall back on the other ways of finding Autodiscover for their domain (ie domain.com, autodiscover.domain.com, or SRV records in DNS).
So yes, Outlook uses Autodiscover (the service) but not necessarily autodiscover.* (the URL) because you can configure the Autodiscover URL to be anything you like for domain-joined clients and they’ll be able to look it up in AD.
Paul,
Long time reader, first time poster. 🙂
I have configured a DAG for a client with the following setup:
Site A = Main Office
Site B = Tertiary (DR)
In Site A I have the EX01 server
In Site B I have the EX02 server
In Site B I have the FSW
Split DNS is configured with mail.domain.com pointing to both EX01 and EX02 as above.
I have some questions based on HA and SR.
1. We have an issue when, for whatever reason, the VPN between Site A and Site B goes down, Outlook clients at Site A cannot connect to Exchange. Is this because the FSW server is in Site B and should be in Site A?
2. I have DNS Made Easy failover in place in the event of an outage the mail.domain.com points to the tertiary. Should I, in the internal DNS, point the clients to mail.domain.com on the tertiary server’s external IP as part of the split DNS Round robin configuration?
3. In the event the office is down and users connect to the RDP server located at the Tertiary location, will they have issues connecting with Outlook?
Thanks Paul.
1) That is a question of DAG behaviour. When the link is down EX01 is isolated and EX02 + FSW are able to form quorum, so I would expect the databases will then be active on EX02. Anyone not able to connect to a CAS that can then proxy them to EX02 won’t be able to connect to their mailbox.
2) I don’t quite understand your question. But if your site to site link is down, clients need to be able to connect to a CAS that can proxy them to the active mailbox database(s).
3) Wherever they are using Outlook from, as long as it can connect to a CAS that can connect to the active mailbox dastabase copy then it should work.
Good article in a rather surprisingly sparse 2013 HA and SR documentation space. This DNS ‘load balancing’ is certainly interesting feature, particularly for small business, but in my tests it did not work very well – I guess too much depends on particular clients, DNS records configs (TTL still do matter – by MS recommendation need to set them to 5 min), etc. I’m looking forward to next article with LB solution. Anytime soon?
Also, the issue with directing users to particular datacenter – is it resolvable at all? Or we stuck with having datacenter load balancing instead of datacenter failover? Its important in many cases as I personally don’t see any point for users in Georgia connecting to CAS in California only to be proxied back over already loaded WAN to Georgia located mailboxes. And vice versa. It could only be useful when disaster strikes. But under normal working conditions is there anything we can do to ensure users are only connected to datacenter where their mailboxes actually are?
Hi Paul! Great Job!
Just one thing that I’m trying to accomplish but I’m not sure!
I have two datacenters where there one DAG each wtih active database. There is a CAS in each datacenter also.
Here’s the cenario:
DC A: 2 MBX / 2 CAS – Active/Passive Mailbox Database – SUBNET A – AD SITE A
DC B: B MBX / 2 CAS – Active/Passive Mailbox Database – SUBNET B – AD SITE B
In the Datacenter A there’s dozen of other sites that connect to Exchange Server using the single name space “mail.corp.com”
There’s a security policie in the Datacenter B where we need that the users in the site B always connect to this site.
I have this:
mail.corp.com – 192.168.0.1 – SUBNET A
I add this
mail.corp.com – 172.16.0.1 – SUBNET B
So, I want the users in the site B always use 172.16.0.1 not 192.168.0.1.
How can I reach this configuration? I can’t use Single namespace in this scenario.
In the Exchange 2010 we have CAS ARRAY that I configured per site, but in Exchange 2013 I’m no sure about this.
Thanks in advance.
Diego
I have to ask, what is the point of splitting the DAG over two sites if users are only allowed to connect to one of them?
Hi Paul!
The Datacenter A will have the most users from the environment!
The Datacenter B, because of security policies of the Country has to have they email system in this Datacenter! In this case I need to configure a way to this uses only connect to this site!
The fact is how do I configure a specific name space for this site!?
Thank you for your reply!
Configure the CAS Outlook Anywhere hostnames in that site with the name you want them to use.
If they require mail to be hosted only in that datacenter then it seems like a breach of that policy to have the DAG span two sites.
did you think about geo dns?
will give these users this answer and these users that answer(different datacenters, one namespace)
How I can configure a Exchange 2013 mailbox manually in outlook when a different user is logged in?
Hi Paul, great job here!
Finally this sorted out the problems back with 2010 and you had no budget for more than 2 Exchange server. 🙂
Little question. My outlook 2010 takes well more than 20 seconds to reconnect, once I take down one of the two legs. I figured you have to add the time of the DAG failover, but still I’m wondering if this could be minimized.
There’s any way to reduce the TTL in the RR scenario, so the connection goes to the other address more quickly?
Also, there’s any difference using OL 2010 and 2013 in autodiscover?
Thanks!
I can’t really make any claims to how fast or slow the clients will handle failovers in different prod environments. The TTL doesn’t really matter here, you’re serving up 2 or more DNS records and the client determines when one is unavailable and tries the other. It works, but your mileage may vary. If you want faster, more robust HA then a load balancer would be worth looking at.
Hello Paul ,
I do not understand why the last server is only one mailbox server and not a combined server just like the other two ? Is it not possible to solve this with the round robin of three cas servers?
I imagine a DAG with three members and a dynamic quorum, which in one case might be losing two members (at a sequential shut down) and then still be able to run the CAS / MBX on one member.
In your case if you are running dynamic quorum and you have the misfortune of the first two servers go down you are left without CAS and thus without the ability to send / receive email. I know this solution is not an optimal HA solution with dynamic quorum. But I believe if two servers go down at the same time, my third will do it too. So I expect that I have all three servers up or not , but that the possibility exists for a service window to shut down a server and get an error on my second server, giving me the access I need a third server and dynamic quorum.
That is just how I happen to have my lab running. For the purposes of demonstrating CAS HA you can pretend that server doesn’t exist if you like.
Hi Paul,
I Have 4 Server, 2 as CAS Server Role and 2 as Mailbox Server Role. I have succeed set CAS High Availability (Thanks to you 😀 ).
I would like to try :
This Case :
OutlookAnyWhere : mail.exchange2013.com
CAS1 : cas2k1301.exchange2013.com
CAS2 : cas2k1302.exchange2013.com
OutlookAnyWhere : mail2.exchange2013.com
CAS1 : cas2k1301.exchange2013.com
CAS2 : cas2k1302.exchange2013.com
Can i set OutlookAnyWhere with multi name space for same CAS Server Role?
Regards,
Rengga
Outlook Anywhere can have both an internal and external URL. They can be different if you like. Best practice is to keep them the same and use split DNS to manage internal vs external name resolution.
Hi Paul,
I have a Exchange 2013 cu2 deployment on HyperV VM on 2008 R2 standard (say exchange01). A snapshot was taken and deleted. If I shutdown the VM a merge will happen and the consequences are not clear. I cant add the VM to a high availability group due to standard windows on exchange01.
I would like to add another physical machine (say exchange02) move all the mailboxes from the first to the second and then shutdown the VM for a merge. In essence a manual high availability, disaster recovery move.
There is not much literature on two separate exchange servers on the same domain without a DAG. I have full access to the running exchange01.
My questions are:
1. Is this the right step. Any other way to save exchange01.
2. Can I move mailboxes on two separate servers on the same domain without DAG? Whats the best way to move the mailboxes? Should I make a recovery database and use dial tone portability or batch move through EAC?
3. If I add the second exchange server will it disrupt the operations of the first in any way?
4. How can I make the move transparent for the outlook client.
5. Any other advice will be much appreciated
Alternate
1. Can I use a backup of the virtual machine through windows backup to do a restore on a physical server as listed at http://technet.microsoft.com/en-us/library/dd876874%28v=exchg.150%29.aspx
Thank you
P.S Great job on the site. Concise pertinent information.
Yes you can install as many servers in the org as you like without creating a DAG. There’s nothing unusual about that.
Yes you could move all the mailboxes across to reduce the risk/impact of the snapshot merge on the first server.
Moving mailboxes is safer than trying to do a database portability or recovery operation.
I of course recommend you take backups of your databases before you do any of this.
Outlook should connect to the second server just fine after the mailbox is moved, no action required by user.
Hopefully by now you learned not to snapshot Exchange servers, which is an unsupported operation.
Pingback: Exchange Installation Tips | Hope you like it..
Greetings Paul.
In Exchange 2010, the outlook client was looking for a mount point via LDAP query to SCP. In SCP he received URL CAS servera.CAS provided to the Outlook client connection point to register in the mailbox database “RpcClientAccessServer” (CAS Array or CAS server). After all this Outlook client connected to that point.
At the moment, I do not understand the principle of autoconfiguration mail clients Outlook with Exchange 2013 🙁
Outlook looks for the mount point via LDAP query to SCP. In SCP he gets URL CAS server. What setting gives CAS server to the client Outlook?
After auto-configuration , the Outlook client has connection point (server name ) “234b- 34545 -dg435.name.me”, proxy name mail01.name.me ( internal Anywhere URL)
What is “234b- 34545 -dg435.name.me”?
Why “proxy name” in the Outlook client has an internal Anywhere URL, but not the external Anywhere URL ( this setting is registered on the server ) ?
Paul:
I’m strongly considering implamenting the round robin DNS as you suggest but I’m fearful of what happens when one server is down. The DNS won’t know this server is down and will continue to serve request to the invalid IP resulting in continuous errors until both servers are connected again right?
Once a connection with Outlook and a CAS is made does it maintain that connection until it is lost or does it try to hit the single FQDN each time and therefor result in an error 50% of the time when there is an outage?
Towards the end of the article I talk about what happens to Outlook when I shut down one of the servers.
For long term outages you would remove the offline server’s IP from DNS to prevent clients from trying to connect to it.
For better HA experience for end users you would implement a load balancer.
I guess we would have to implement two load balancer to keep from having a single point of failure. I appreciate the help.
Hi Paul,
Would NLB not be an improvement on RR in the event of one server being off the air, as users would automatically be redirected to the live server? Or am I missing something here !
My opinion is that the HTTP client (eg Outlook, IE) is smarter at detecting a failure.
Remember NLB only detects if an entire server is down. If just one service (like OWA) is failing then it won’t know and will keep directing traffic to it. And because the client only has one IP to connect to (the NLB VIP) it can’t decide to try another IP instead, as it can with DNS RR.
The only advantage I see with NLB is that will actually *load balance* the traffic as opposed to DNS RR which will not (it will just semi-load balance as clients randomly choose one or the other DNS record).
But if true load balancing like that is required in your environment then a proper load balancer (like an F5 or a Kemp Loadmaster) would be much, much better than NLB.
Hi, i have two network connection on my exchange server 2013 one for internet and another for local network my problem is when i enable internet network connection exchange server services stop and ECP doesn’t open in my organization but when i stop the internet network connection everything works fine and ECP open in my organization … whats the problem ? what can i do for this … thanks
Why use two network connections like that?
Hi,
I have two cas servers on two location’s on 2 subnets
What i want if cas server on site 1 is down the clients on site go to the cas on site 2
Can that be done automaticly in stead use of round robin ?
Yes, using a load balancer.
Hi Paul
Can you please have a look at my earlier posts above and provide some input?
Kind Regards,
JP.
Hi Paul, I can’t argue with that and you certainly know what you are talking about.
Thanks for all the good advice.
Hi again, they do if you tell them to. Picture this…
EX01.local = 192.168.1.10
EX02.local = 192.168.1.11
DAG1 = 192.168.1.12
Set-OutlookAnywhere = mail.local
Set DNS mail.local = 192.168.1.12
Create Computer account called Mail.
Autodiscover sets users to connect to mail.local which is 192.168.1.12. EX01 (1.10) and Mail (1.12) are both set as this is the active database holder..
EX01 (1.10) goes down and the DAG IP (1.12) instantly moves to EX02(1.11). The client is still pointing to Mail on 1.12 but it is in fact now the other server. The cluster service moves the 1.12 IP in 1 second from EX01 to EX02.
I have had this running in 2010 for a few years with no problems. My current test lab for Ex 2013 is set up like this and seems to work very well.
Cheers
No. What you’ve got there is a hack that happens to work because you’re running multi-role servers, but is incorrect as far as the actual Exchange server role architecture works (in both Exchange 2010 and 2013).
It is not correct to point your client namespaces at the DAG IP and you should not recommend it to anyone.
Exchange 2016 no longer has separate roles. So would this still be considered a “hack”?
Hi Paul, Thanks for the great article. What do you think of this as an alternative to the round robin DNS?
Create the single name space as you described, however in DNS point that record to the DAG IP address. Then the client is always pointing to the active server when the DAG IP moves in the event of a server shutdown or failure. I have tested this and it seems to work fine. If i ping the DAG IP, I only loose 1 packet when the server shuts down and the IP moves to the other server. The client remains connected.
Cheers
Clients don’t connect to the DAG IP address, so no, you should not point the DNS record for your Client Access server namespaces at the DAG IP address.
Hi David
The CAS Array in Exchange 2013 doesn’t exist anymore but the grouping of CAS Servers “ARRAY or Load balance” does exist.
Trying to Avoid the below 2x points:
Internal users that have mailboxes hosted on mounted DB’s located in site A connecting to Site B CAS Servers/ internal CAS Load balancer URL if there is no disaster.
Internal users that have mailboxes hosted on mounted DB’s located in site B connecting to Site A CAS Servers/ internal CAS Load balancer URL if there is no disaster.
Trying to achieve the below 2 points:
1.Internal users to connect to Site A, CAS Array/internal CAS Load Balancer URL if they have mailboxes mounted DB’s hosted in site A, and ONLY connect to site B CAS Servers/array in the event of a disaster.
2.Internal users to connect to Site B, CAS Array/internal CAS Load Balancer URL if they have mailboxes mounted DB’s hosted in site B, and ONLY connect to site A CAS Servers/array in the event of a disaster.
How do I achieve this Please advise.
There’s high availability, and then there is site resilience. HA is for general faults and failures like a server being down, SR is for full DR situations.
HA can be automatic. SR tends to require manual intervention, as is appropriate for a full blow DR situation.
There are also a lot of factors that go into designing HA and SR. Are the two physical locations the same AD site, or two different AD sites? What is the connectivity and bandwidth between each data center? What is the bandwidth and connectivity between the data centers and the client locations? How many DAG members are at each site? What load balancers (if any) are available? So on and so on.
Giving you a solution here in a comments section is impossible. But I would encourage you to think about the *simplest* possible solution you can put in place. A lot of networks can easily handle clients connecting to either data center regardless of where their mailbox happens to be active at the time.
JP,
I have exactly the same scenario as you here!
Did you ever get a working solution to this?
Thanks
Darren
Hi Paul
Thanks for the Great Article. Can you please explain the requirements and configuration, for 2 sites? each containing 2 Multirole Exchange 2013 Servers. If we make use of a single name space would that not cause 50% of the users to connect to the DR site CAS “Array” and they would have to traverse the WAN to get to their active mailbox server?
I would like to know how you get around this? Both my sites will have active mailbox users & I would like each site to connect to it’s own CAS Array name. in the event of a disaster the sites should fail-over to each other. What are my requirements?
Kind Regards,
JP
Hi JP,
i would recommend that you mount the database of users of site A in site A and have copy of the database in site B and also the same for site B mount the database in site B and have a copy of in Site A since exchange 2013 is more aware of where the database of specific user is found and will direct the CAS to where the database is active. When an incoming client connection must be processed, CAS looks up Active Directory to find details of the mailbox via its GUID and Active Manager will tell CAS what mailbox server currently hosts the active copy of the database.
Regards
David K
Thanks David.
Just a bit of background, I would like to deploy the following:
Site A: 2x CAS Servers & 2x MBX servers. Site A also has the Internet Breakout & reverse proxy.
Site B: 2x CAS Servers & 2x MBX Servers. Site B has no Internet breakout.
The DAG will be configured as per your post above, split across both sites containing all 4x MBX servers, Site A users database mounted in site A with copy in site B, and Site B users database mounted in site B with copy in Site A
Site A CAS Servers will be deployed in a CAS Array for that site Single name space for that site
Site B CAS Servers will be deployed in a CAS Array for that site Single name space for that site
I however need to ensure that only SITE B users connect via SITE B CAS Array & only Site A users connect via SITE A CAS array.
I would like to avoid a 50% split in CAS proxy traffic across the WAN, if any of the sites fail and I would like to provide site resilience. how would you recommend I do that?
I will configure the internal URL’s on Outlook anywhere for both site A CAS servers to reflect CasarraysiteA.company.local
and
I will configure the internal URL’s on Outlook anywhere for both site B CAS servers to reflect CasarraysiteB.company.local
The External URL’s for both sites will be configured as: owa.company.com, which will point to the CAS Servers in Site A this should cause external connecting users who have mailboxes hosted in site B to be proxied across the WAN to site B CAS Servers. {which is fine}
I would like to know from an internal connectivity perspective, if Site A CAS Servers would fail what is required to be performed to provide site resilience? so users would then connect to Site B Cas Array servers and be proxied across the WAN to Site A MBX server where the mailbox DB is mounted.
And
I would like to know from an internal connectivity perspective, if Site B CAS Servers would fail what is required to be performed to provide site resilience? so users would then connect to Site A Cas Array servers and be proxied across the WAN to Site B MBX server where the mailbox DB is mounted.
Kind Regards,
JP
Hi JP,
Well first to get things straight there is no such thing as CAS Array in Exchange 2013 they have removed this and it is found in exchange 2010. also having two different site name will kick out the HA of Exchange in your organization in case the servers in site B goes down the users will not automatically switch the servers in site A since you only limited the site to two servers in the configuration you have set in outlook anywhere.
If you read up in Paul article you will see how he set up the outlook anywhere to be the same across the site and let outlook and exchange deal with finding the where the mailbox is active over http/https.
You can add additional IP address on primary CAS server for CAS Array hostname. With unstable NLB uninstalled. If primary CAS goes offline, just add the same additional IP to another CAS. That way you have control of CAS servers.
Probably the same way can do with exchange 2013 single namespace.
There is no CAS Array hostname in Exchange 2013. And moving IP addresses around manually is not a very good HA strategy.
For example, on Exchange 2010 with CAS Array and 2 NLB nodes mail flow sometimes stopped completely (on two different NLB setups). To restore mail flow i had to disable enable NLB Ethernets…
Uninstalled NLB and implemented additional IP for primary CAS Array node, so far works very stable.
Similar solution works for Exchange 2013 external links too…
No need for NLB, HWLB, DNS…
Of course this will not be suitable for all deployments.
Hi Paul,
Just wanted to check with you about the configuration you stated up
you are saying there is no need for load balancing exchange with NLB or a load balancer?
what if you have exchange server published through TMG or UAG or any reverse proxy how will that work with out having a virtual ip to publish to TMG or any reverse proxy software as they are not aware of rpc/https or autodiscover and works either with FQDN or ip.
thank you
David K
I didn’t say there is no need for load balancing.
If you’re publishing multiple CAS in TMG you can let TMG do the load balancing for you.
Hi Paul,
Regarding this issue, I read that the propper NLB should have service awareness (L7 NLB).
Meaning, if the server is online but the service is down, the NLB will automaticaly fialover to the other available servers.
However, I can’t seem to find any good info on this.
Do you have any recommendation?
Will TMG do the job, or will it just send the information using DNS RR?
Windows NLB does not have service awareness.
TMG is end of life.
If you need robust L7 load balancing with service awareness then look at a load balancer from a vendor such as Kemp or F5.
Hi everyone
My System had 4 exchange 2013 (2 Database DAG and 2 CAS). rpc/https is Unstable. when i modified Database or move mailbox is outlook client disconnect (but webmail is normal) …and waiting 1-2h it reconnected.
Now, I still have not fixed. Who can help me…
Thanks
Hi Paul and thanks for another great tutorial!
Wonder when your next wil come out.At the end of this post you mentioned the following:
In upcoming articles we’ll look further at load balancing options for Exchange 2013 CAS, as well as how to configure the external hostname and the SSL options for Outlook Anywhere.
Hope its out soon,and keep up the good work!
Hi Paul,
I have 3 physical Servers .
one for Domain controller.
two for Exchange 2013. I need to have high availability for exchange server 2013.
Honestly speaking I am new to exchange high availability feature.
I am planning to have installed mailbox and CAS roles on both the servers. And what is this witness server for high availability.
What are the license requirements for the high availability of Exchange 2013.
Paul,
Nice article, can you please clarify how Outlook updates itself, with the changes made. I mean you mentioned that within 30 minutes its updated, so the TTL for EXPR provider has it changed in 2013.
Also is there a CAS array in 2013, and can it be bound to a site.
Thanks
Gopinath T
Paul,
One thing I just thought of, if you have four exchange servers, two primary and two in a DR Data center over a WAN link, if I create a single namespace and put all four servers in it, won’t the traffic spread across all four and cause 50% of the people to attach to DR CAS servers, in which then have to come back across the WAN links to get the data, then transmit it back over the WAN links again?
Do you have to leave out the DR from the DNS round robin, them manually add them in the event you lose both primary servers?
The DR subnet is in its own AD Site.
Randy
I have been trying to understand this, but not much avail. The below is what I have seen in exchange 2010 sp3
Site A – CAS Array name – SiteA-CA — Site B – SiteB-CA
When clients whose MBDB is on Site A Mbx server, Outlook talks to SiteA-CA, when the DB failsover to a MBX server on Site B- the Client changes the end point to SiteB-CA(redirection over proxy, I think this happened somewhere after SP2 RU2).
I am assuming that the same concept applies in Exchange 2013 as well, unless someone corrects me.
To answer your question in 2010 world – 2 Datacenters in 2 diff sites, cant be part of same CAS array name, question is how is it achieved in Exchange 2013.
Thansk
Gopinath T
In 2013 there is no CAS Array so the CAS namespace is no longer limited to the AD site boundary.
So basically with a proplerly configured single name space, you do not need NLB anymore it seems?
It seems this 20 sec switchover will work the same whether the CAS is loaded on the Mailbox or on a separate server?
NLB wasn’t a good option for Exchange 2010 anyway.
With Exchange 2013 I see absolutely no need to run NLB in any scenario. As it stands right now I doubt I will ever recommend it to a customer.
Paul,
Thank you! you made my day. I opened a ticket with Microsoft and two different engineers told me with exchange 2013 if you create separate CAS Servers you need a NLB. It is like they are stuck in the 2010 world.
Thanks,
Randy
Dear Randy,
NLB is use to divide load between servers, if you don’t implement then there is no way by which you divide load among servers. thats what MS guys ask for NLB.
may be one of CAS servers is under heavy load and 2nd is idle..can you transfer the load to the idle server ?
Regards
:-o) that’s hilarious,
So what is the recommended way to provide High Availability for the 2x Virtualized CAS 2013 servers ?
Paul, you say in this article:
We can configure a single namespace for these instead of the unique server FQDN for each. Note that when configuring the InternalHostName you also need to set the InternalClientsRequireSSL option as well. To keep this example simple I am not requiring SSL for internal clients.
Are you saying you should ncrease security on the LAN with ssl and you actually don’t need to set that but then the internal traffic will not be encrypted??
Thanks!
SSL for internal clients is not required as default. You can turn it on if your “Internal” clients are actually connecting via what you would consider a hostile network (which some people consider *all* networks to be).
Despite the non-SSL the auth credentials are not passed in the clear anyway, which is probably what some people will be immediately concerned about.
It isn’t insecure to run it that way but I suspect many customers will enable SSL requirement for internal clients.
What about Windows NLB instead of DNS round robin?
will it make any issues?
It has several limitations and issues and no real advantage over DNS RR that make up for them so I don’t think NLB is worth doing for Exchange 2013. That is my opinion anyway.
Paul, great work. Quick question here. In the scenario where the CAS role is broken out to separate front-end servers (configured per above) and the mailboxes are on 2 more servers which are setup with a DAG (per your other article), what additional steps, if any are needed to ensure seamless failover in the event that the first server in the DAG goes toes up. How are the front end servers connecting/checking the mailbox servers for availability and for which server to connect to?
Cheers
The CAS is aware of where the active mailbox database copy is in the DAG. It queries the Active Manager for the DAG. There’s no additional config required.
You can read more about Active Manager here if you like. It is a good concept to understand:
http://technet.microsoft.com/en-us/library/dd776123(v=exchg.150).aspx
Hi Paul,
if i want to configure only two server with mailbox +cas on each one , how i can configure dns and certificate request?
i want to configure dag for mailbox HA and round robin for cas HA ok ?
example:
server 1 192.168.1.1/24
server2 192.168.1.2/24
for dns i have need to configure a single namespaces for cas high avaiability correct ? :
a record mail.mydomain.com —>> 192.168.1.1
a record mail.mydomain.com—>>>192.168.1.2
in my dns enviroment i have need to configure other two records for autodiscovery service or just that above ?
how can configure virtual directory such as ecp,ews,owa,outlook anywhere ecc for redundant cas ?
can you explain me how to configure certificate request for each one of this service ?
thank you so much
Mattia Lodi
I’ve replied to your forums thread here:
https://www.practical365.com/forums/exchange-server-2013/4282-problem-high-avaibility-cas-configuring-dag.html
Paul,
Great article!
The link you specified doesn’t work.
I was mostly interested in the internal/external hostname configuration on both of the CAS servers as I’ve got very similar setup to what you presenting here.
Currently I have two separate names mail.domain.com (for primary) and owa.domain.com (for standby). Do you think i should re-point the standby CAS virtual directories to the same FQDN of mail.domain.com and scrap the owa.domain.com ?
Also do I need to configure the Outlook Provider or keep it blank? Currently set to mail.domain.com.
Thanks.
Recently clean-installed Exch2016 and trying to bone-up on a HA strategy for 2016… slim pickings as it’s so new.
Reading 2013 articles to learn more about implementing HA and found the link above to be broken.
Thx.
Those forums no longer exist.
The typo on the 3rd server is a little confusing, but then it says “the trouble starts when E15MB goes offline”?! Which server is that?
Not my finest proof-reading effort. Both errors fixed now.