At my IT/Dev Connections session in September I advocated for simple designs for database availability groups. This included some points about Exchange Server 2013 storage design and layout, such as:
- JBOD vs RAID
- Multiple databases per volume
- Volumes mounted in folders not drive letters
- Co-locate the database and transaction log files on the same volume
Those recommendations came with caveats of course, depending on various factors. Aside from simple designs providing ease of management they can also mean you get to leverage the terrific new feature in Exchange Server 2013 called Autoreseed.
Autoreseed in Exchange Server 2013
With Autoreseed the members of an Exchange 2013 DAG are pre-configured with one or more spare volumes. When a disk fails the Exchange server is able to automatically replace the failed disk with a spare, and then reseed the lost database copies to the new volume.
This means the recovery workflow in Exchange 2013 goes like this:
- Disk fails (resiliency of your DAG is impacted)
- Spare disk automatically mounted
- Database copies reseeded (resiliency is restored automatically)
- Manual intervention to replace failed disk replaced with a new spare
In Exchange Server 2010, which also supported JBOD storage, the recovery workflow goes like this:
- Disk fails (resiliency of your DAG is impacted)
- Manual intervention to replace disk
- Manual intervention to reseed database copies (resiliency is restored)
The Exchange 2010 recovery workflow involves too many manual steps to restore the resiliency of the DAG, requires response by admins at any hour of the day, and is simply not efficient at scale.
The Exchange 2013 recovery workflow can automatically restore the resiliency of the DAG without manual intervention, requires response by admins at a lower urgency, and is far more efficient at scale.
Laying the foundation for Autoreseed involves implementing those recommendations I mentioned earlier. Let’s take a look at them in a little more detail.

RAID vs JBOD
For single datacenter deployments:
- Always use RAID for the system/OS volume
- Always use RAID when there are less than 3 database copies
- Use JBOD when there are 3 or more database copies
- Use JBOD for lagged copies only when 2 or more lagged database copies exist
For multiple datacenter deployments:
- Always use RAID for the system/OS volume
- Always use RAID when there are less than 2 database copies in a datacenter
- Use JBOD when 2 or more database copies exist in a datacenter
- Use JBOD for lagged copies as long as 2 or more lagged copies exist, or log play down is enabled
Multiple Databases Per Volume
Use multiple databases per volume when 3 or more database copies exist. Can be placed on RAID or JBOD (with preference for JBOD as I’ll explain shortly).
The number of databases per volume should equal the number of copies of the databases.
Volumes Mounted in Folders not Drive Letters
Mounting your volumes as drive letters is fine for non-DAG deployments, and works for DAG deployments as well, but is not recommended.
There is the obvious limitation of the size of the alphabet. With only 23 usable letters after A:, B:, and C: are consumed, and Exchange 2013 Enterprise capable of hosting 100 databases, you can easily run into problems or at the very least find yourself juggling a complex configuration to work around it.
Instead mount your volumes as folders, using a RAID-protected host volume (the C: volume for system/OS is fine for this).

Co-Locate Database and Transaction Log Files
Exchange admins are used to placing the database and transaction log files on separate volumes for recoverability from disk failures. This is still recommended for non-DAG scenarios.
For DAG scenarios the fact that you have multiple copies of each database mitigates the risk of a single disk failure taking out an entire database. So co-locating the database and transaction log files is recommended for DAG scenarios, especially when using multiple databases per volume, and also when using JBOD.
Combining the above, along with evenly distributed active, passive and lagged database copies, gives you an Exchange 2013 DAG that looks similar to this example.
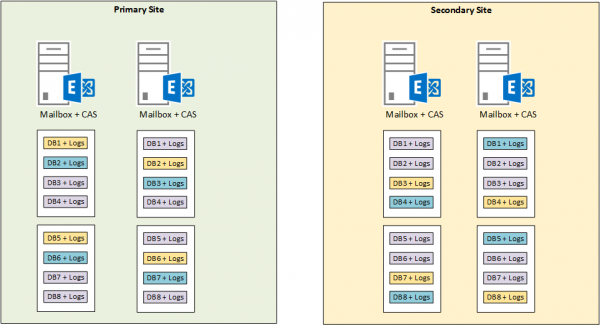
This example obviously assumes that a four node DAG in two datacenters is the right solution for the environment. Your own requirements will vary of course, but this example is being used mainly to demonstrate Autoreseed.
Example Storage Layout for DAG Members
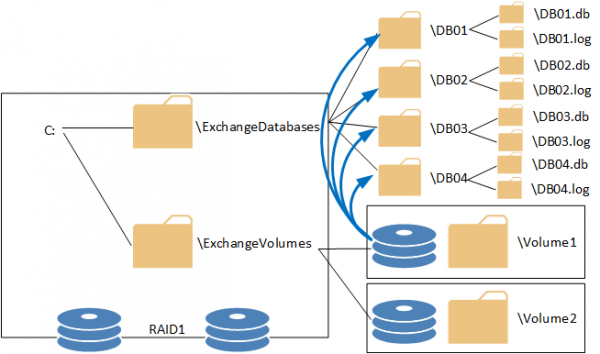
With all of the above in mind here is an example of how the storage layout would be configured for an Exchange 2013 DAG member.
We start with a RAID protected system/OS volume, and create two folders in the root of C:.
- ExchangeDatabases
- ExchangeVolumes
These match up with the default settings of an Exchange 2013 DAG for root folder paths.
[PS] C:\>Get-DatabaseAvailabilityGroup | fl *autodag*path AutoDagDatabasesRootFolderPath : C:\ExchangeDatabases AutoDagVolumesRootFolderPath : C:\ExchangeVolumes
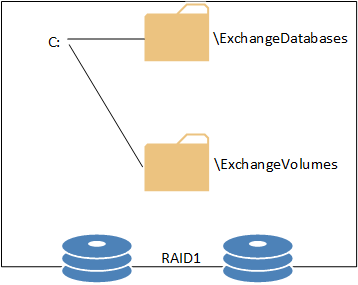
Next, the volumes that will be hosting the databases and log files are configured. For this simple example a single volume is being configured to host active data and a single volume is being configured as a spare. These are mounted into sub-folders of C:ExchangeVolumes named Volume1 and Volume2.
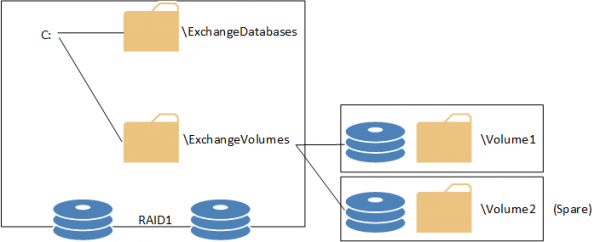
Volume1 is then mounted into additional folders for hosting the database and log files. These folder names match the names of the databases in the DAG, for example DB01, DB02, DB03 and DB04. These are created as sub-folders of the C:ExchangeDatabases folder.
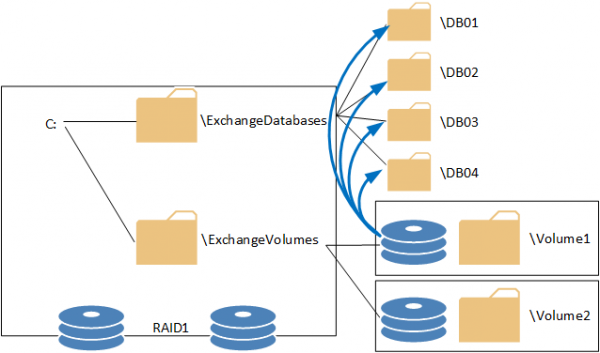
If you’re wondering what I mean by this, all I am referring to is mounting the volume into multiple paths instead of as a drive letter, just as you would normally see when first creating the volume.
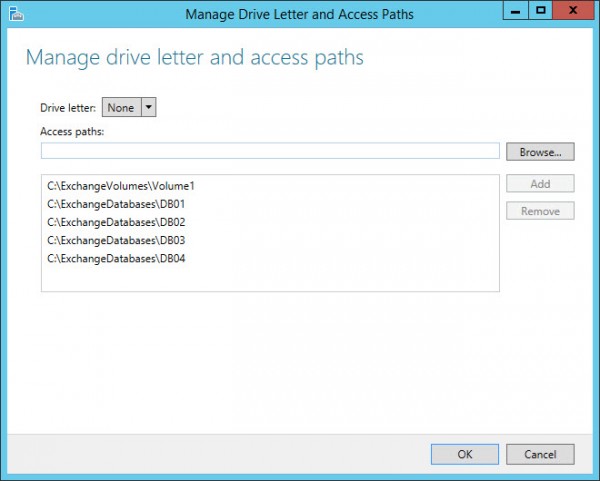
Finally, create sub-folders of each database folder to host the DB and log files. These are named according to the database names again, so DB01 needs sub-folders named DB01.db and DB01.log.
These folders are then used as the paths when creating the mailbox databases themselves. For example, here are the paths for DB01 in this environment.
[PS] C:\>Get-MailboxDatabase DB01 | fl *path* EdbFilePath : C:\ExchangeDatabases\DB01\db01.db\DB01.edb LogFolderPath : C:\ExchangeDatabases\DB01\db01.log
Autoreseed in Action
When a disk fails in an Exchange Server 2013 DAG member the Autoreseed workflow begins. However, the following conditions must be met for Autoreseed to take place:
- The database copies are not blocked from resuming replication or reseeding.
- The logs and databases files for the database are collocated on the same volume.
- The logs and database folder structure matches the naming convention required for Autoreseed.
- There are no other database copies on the volume that are in an “Active” state.
- All database copies on the volume are in a “FailedAndSuspended” state.
- The server has no more than 8 “FailedAndSuspended” database copies.
If those conditions are met then Autoreseed can attempt to resolve the issue.
The workflow begins with detection of the failed volume. Database copies are regularly checked to see whether any of them have been at a status of “FailedAndSuspended” for 15 minutes or longer. This is the state that a database copy will be in when there is an underlying storage issue. The 15 minute threshold exists to ensure that remedial action is not taken too quickly.
Log Name: Microsoft-Exchange-HighAvailability/Seeding Source: Microsoft-Exchange-HighAvailability Date: 2/09/2014 10:19:46 PM Event ID: 1109 Task Category: Auto Reseed Manager Level: Information Keywords: User: SYSTEM Computer: MELEX1.exchange2013demo.com Description: Automatic Reseed Manager is starting repair workflow 'FailedSuspendedCopyAutoReseed' for database 'DB01'. WorkflowLaunchReason: Database copy 'DB01\MELEX1' encountered an error during log replay. Error: The system cannot find the path specified
The server attempts to resume the FailedAndSuspended database copy 3 times.
Log Name: Microsoft-Exchange-HighAvailability/Seeding Source: Microsoft-Exchange-HighAvailability Date: 2/09/2014 10:19:46 PM Event ID: 1124 Task Category: Auto Reseed Manager Level: Information Keywords: User: SYSTEM Computer: MELEX1.exchange2013demo.com Description: Automatic Reseed Manager is beginning attempt number 1 of execution stage 'Resume' for database copy 'DB01' as part of repair workflow 'FailedSuspendedCopyAutoReseed'. WorkflowLaunchReason: Database copy 'DB01\MELEX1' encountered an error during log replay. Error: The system cannot find the path specified
Log Name: Microsoft-Exchange-HighAvailability/Seeding Source: Microsoft-Exchange-HighAvailability Date: 2/09/2014 11:04:46 PM Event ID: 1119 Task Category: Auto Reseed Manager Level: Error Keywords: User: SYSTEM Computer: MELEX1.exchange2013demo.com Description: Automatic Reseed Manager failed to resume database copy 'DB01' as part of repair workflow 'FailedSuspendedCopyAutoReseed' after a maximum of 3 attempts. The workflow will next attempt to assign a spare volume and reseed the database copy. WorkflowLaunchReason: The Microsoft Exchange Replication service is unable to create required directory C:\ExchangeDatabases\DB01\db01.log for DB01\MELEX1. The database copy status will be set to Failed. Please check the file system permissions. Error: System.IO.DirectoryNotFoundException: Could not find a part of the path 'C:\ExchangeDatabases\DB01\db01.log'.
The server attempts to assign a spare volume once per hour for up to 5 attempts.
Log Name: Microsoft-Exchange-HighAvailability/Seeding Source: Microsoft-Exchange-HighAvailability Date: 2/09/2014 11:04:46 PM Event ID: 1124 Task Category: Auto Reseed Manager Level: Information Keywords: User: SYSTEM Computer: MELEX1.exchange2013demo.com Description: Automatic Reseed Manager is beginning attempt number 1 of execution stage 'AssignSpare' for database copy 'DB01' as part of repair workflow 'FailedSuspendedCopyAutoReseed'. WorkflowLaunchReason: The Microsoft Exchange Replication service is unable to create required directory C:\ExchangeDatabases\DB01\db01.log for DB01\MELEX1. The database copy status will be set to Failed. Please check the file system permissions. Error: System.IO.DirectoryNotFoundException: Could not find a part of the path 'C:\ExchangeDatabases\DB01\db01.log'.
Log Name: Microsoft-Exchange-HighAvailability/Seeding
Source: Microsoft-Exchange-HighAvailability
Date: 2/09/2014 11:04:46 PM
Event ID: 1125
Task Category: Auto Reseed Manager
Level: Information
Keywords:
User: SYSTEM
Computer: MELEX1.exchange2013demo.com
Description:
Automatic Reseed Manager has successfully assigned spare volume '\?Volume{6e77b6f8-6f83-49f1-ae48-60aa9419cd19}' mounted at 'C:\ExchangeVolumes\Volume3' for database copy 'DB01' as part of repair workflow 'FailedSuspendedCopyAutoReseed'. The workflow will next attempt to reseed the database copy.
WorkflowLaunchReason: The Microsoft Exchange Replication service is unable to create required directory C:\ExchangeDatabases\DB01\db01.log for DB01\MELEX1. The database copy status will be set to Failed. Please check the file system permissions. Error: System.IO.DirectoryNotFoundException: Could not find a part of the path 'C:\ExchangeDatabases\DB01\db01.log'.
The server attempts to reseed the database copies to the new volume, with up to 5 attempts at 1 hour intervals.
Log Name: Microsoft-Exchange-HighAvailability/Seeding Source: Microsoft-Exchange-HighAvailability Date: 2/09/2014 11:19:46 PM Event ID: 1117 Task Category: Auto Reseed Manager Level: Information Keywords: User: SYSTEM Computer: MELEX1.exchange2013demo.com Description: Automatic Reseed Manager throttled repair workflow 'FailedSuspendedCopyAutoReseed' for database 'DB01'. Details: The Automatic Reseed Manager encountered an error: The automatic repair operation for database copy 'DB01\melex1' will not be run because it has been throttled by the throttling interval of '01:00:00'. WorkflowLaunchReason: The Microsoft Exchange Replication service is unable to create required directory C:\ExchangeDatabases\DB01\db01.log for DB01\MELEX1. The database copy status will be set to Failed. Please check the file system permissions. Error: System.IO.DirectoryNotFoundException: Could not find a part of the path 'C:\ExchangeDatabases\DB01\db01.log'.
Log Name: Microsoft-Exchange-HighAvailability/Seeding Source: Microsoft-Exchange-HighAvailability Date: 3/09/2014 12:10:17 AM Event ID: 826 Task Category: Seeding Target Level: Information Keywords: User: SYSTEM Computer: MELEX1.exchange2013demo.com Description: DB Seeding has completed for the local copy of database 'DB01' (1b3363f6-7f82-41ca-953b-2c295c1896a9).
If the process was not successful after 5 attempts, it stops.
After 3 days, if the database copies are still “FailedAndSuspended”, the workflow begins again.
Summary
As you can see Autoreseed is quite intelligent and effective, resolving a straight-forward issue like storage failure with no manual intervention by the administrator except for replacing the failed disk with a new spare.
Just how good is Autoreseed?
In my test lab I tend to treat my servers pretty rough. To test Autoreseed I would regularly open up Server Manager on a DAG member and offline one of the volumes hosting database copies. Then I would go away and do something else for an hour or two.
Every single time Autoreseed successfully restored the resiliency of my DAG. Looking at the event logs it typically achieves this in a little over an hour. In the real world if there are delays or retries on some of the Autoreseed workflow steps, or the databases are larger and take longer to reseed, then it may take longer to recovery but I would have full confidence that it would work.
Autoreseed is a feature of a highly intelligent server application that is designed to run efficiently at scale. As with many features in Exchange Server 2013 to take full advantage of Autoreseed you design for *simpler* DAGs. This is counter-intuitive for some people who are used to adding complexity to their designs to make them more resilient.
But as you can see, by getting the right foundations in place you can easily to take advantage of the benefits of Autoreseed in your deployment.



Thanks for all the awesome info in the article. I have setup autoreseed in Exchange 2019 with bitlocker volumes. All volumes successfully autounlock after each reboot. When I try to test the event ID’s get to 1149 Disk Reclaimer, it shows two available volumes:
The Volume Manager found the following volumes:
UnknownVolumeCount=0
UnEncryptedEmptySpareVolumeCount=0
EncryptingEmptySpareVolumeCount=0
EncryptedEmptySpareVolumeCount=2
QuarantinedVolumeCount=0
NotUsableAsSpareVolumeCount=18
ErrorVolumeCount=0
ReFSVolumeCount=0
—UnEncryptedEmptySpareVolumeList—
—EncryptingEmptySpareVolumeList—
—EncryptedEmptySpareVolumeList—
D:\ExchangeVolumes\Volume16\ ( \\?\Volume{df9fa9d4-517c-43f0-8d98-e19428a8644e}\ )
D:\ExchangeVolumes\Volume17\ ( \\?\Volume{190fb710-e0ca-4f8f-a8fb-9a525fc5ae0e}\ )
Even though if shows two available volumes it never uses them. It just continues with the repeating errors that the DB is failed.
Any clues?
Thanks!!
It seems that auto-reseed defaults to the active copy of the database as the source.
I would hope to see the reseed prefer a local source over a LAN connection. Throughput does not appear to be part of the auto-reseed logic.
Even when manually reseeding and specifying the source server, any error seems to cause the reseed to revert to the active database copy as the source. I resorted to activating the database copy within the data-center where the reseed was taking place after several attempts to manually specify the source failed.
ウブロブランドコピー(N級品)販売通販専門店
ウブロコピー、ウブロブランドコピー、ウブロコピー時計、
ウブロコピー代引き、ウブロコピー 時計通販、ブランドコピー、
各種海外有名ブランド時計品を豊富に取り揃え、
しかもお客様を第一と考えて、驚きの低価格で提供しております
Hi Paul –
I’ve noticed that my volume label is being renamed to match the directory structure names (Starts as “Volume4” and is renamed to “DAG4_DB2”). Have you noticed this as well? I’m using ReFS with Windows Server 2016 and Exchange 2016 CU7. I’ve been working with MS (an SPFE and their support staff) but they have either only tested with NTFS or couldn’t make their lab work – neither can confirm that this is expected. It hasn’t caused any issues – the reseed completes successfully and the DB copies all return to a healthy status.
I’ve also noticed that if I attempt to simulate more than one disk failure within a few hours (by marking the disk offline), the Auto Reseed Manager goes into a throttled state (event 1117 in the Seeding crimson log). One server has been in this throttled state for 2 days so far – even with restarting the Exchange Replication Service & the spare being listed. I’m going to let it bake through the weekend & see if eventually completes. I’ve read on TechNet that the Disk Reclaimer will only run once every 24 hours (restarting the Replication Service seems to reset this timer) but it makes no mention of this task being throttled or limits on the number of disk failures that its able to process per day, etc..
I haven’t found any web articles to indicate that either of these is expected behavior so I thought I’d ask about your observations. Thanks!
For clarification, it is my spare volume label that is renamed as part of the reseed process.
Rob,
I’m noticing the same thing you indicate in your post about the spare volume being renamed to a database after reseed and have also seen the throttling errors as well. I was wondering if the volume eventually repaired itself over that weekend in March?
Thanks,
Jerry
Hi Paul, please what am I doing wrong? After mounting a volume to DB01 and DB02, if I create folders DB01.db and DB01.lo in DB01, the two folders get created in DB02 automatically. When I also created DB02.db and DB02.log in DB02 mount point, they also automatically got created in DB01. I know have something like below in DB01 and DB02
DB01.db
DB01.log
DB02.db
DB02.log
Whereas, DB01 should only contain DB01.db and DB01.log
If I delete DB02.db and DB02.log from DB01 mount point, they also get deleted in DB02 mount point.
Please, help.
What you’re seeing is normal and expected if you’ve mounted the same underlying volume into two different folder paths. Each folder is basically a view of the same volume, so you’ll see both sets of db and log folders because it’s the same location.
I guessed so. I used VMware workstation to build my lab and the underlying volume used is basically the same for the mount points. I’m trying to follow your implementation as I’m currently watching your videos on Pluralsight in preparation for the exam (70-345). I was wondering and I watched and re-watched your demos, in case I’m missing something. I also purchased your ebook on same subject and read autoseed section to ensure i fully understood the technique and process.
I appreciate your quick response.
It looks a bit weird the first time you do it. Using multiple folder paths to point to the same underlying volume is not all that common in Windows Server admin, so a lot of Exchange admins just haven’t seen it done before.
I am struggling with the spare selection portion of autoreseed:
Where is the spare volume configured? How does Exchange select the volume to mount as the spare? Is it simply looking for a volume with sufficient capacity which is not yet mounted?
Don’t overthink it. I demonstrate in the article above how to configure a simple autoreseed scenario with Volume1 and Volume2 used in the example. Volume1 hosts the databases, Volume2 is the spare. By following the Microsoft guidance for configuring the storage paths, volume names, number of databases per volume, etc, the DAG is aware of what storage is in use and what is available as spares.
Thank you Paul,
So the spare volume mounted in the ExchangeVolumes folder but not in the ExchangeDatabases volume will implicate it as a spare for the DAG.
Once triggered autoreseed will adjust the ExchangeDatabases\ mount points from the failed volume to the spare volume during the reseed?
Much appreciated.
Correct. Exchange does its magic. If it can’t (e.g. if there’s no spare volumes available), autoreseed will fail and log appropriate events to the event log.
https://www.practical365.com/microsoft-exam-70-345-preparation-readiness/?utm_source=espfooter&utm_medium=link&utm_campaign=exam70345
Is there any difference between your pluralsight videos and your books?
Robert
Both cover the same exam objectives.
Hey Paul,
Going through your plural sight videos and trying to make sure i really understand autoreseed. In the past i have had a tough time with understanding autoreseed.
1) C:\ExhchangeDatabases\>DB01, DB02, DB03 DB04> those are mount points, and not folder names on the drive correct?
Example: DB01 would read or show C:\exchangedatabases\db01.db (folder) and db01.log(folder) ?
Instead of c:\exchangedatabases\db01\db01\db01.db db01.log – Correct? I know this this is a psycho question but i just want to make sure i have it down.
For DB01 the paths will end up as:
C:\ExchangeDatabases\DB01\db01.db\db01.edb
C:\ExchangeDatabases\DB01\db01.log
The storage volume would be mounted in C:\ExchangeDatabases\DB01
Right. Ok. So in this case (From your pluralsight videos) its expected that when looking at the DB01 mount point i will also the DB02 folders?
Robert
That’s a design decision that you make. In the example above you can see a screenshot where I’ve mounted one volume for DB01, DB02, DB03 and DB04.
So that is 4 databases per volume, in that example. Which means when I go to C:\ExchangeDatabases\DB01 I will see the sub-folders for all 4 databases and their logs, because its the same underlying storage volume.
I’m seeing this during the Auto Reseed – and I see it in some of your screen shots above. My reseed isn’t starting. What can I do to resolve this?
“Please check the file system permissions. Error: System.IO.DirectoryNotFoundException: Could not find a part of the path . . . . .”
Thank you for your great instructions.!
Dear Paul,
kindly what do you mean by “The number of databases per volume should equal the number of copies of the databases”
Let’s say you have four copies of each database, because you have a four-member DAG and you’ve added a database copy to each DAG member.
In that scenario, it’s recommended to put four databases on the same disk/volume, rather than one database per disk/volume. So you might have 4 x 200GB databases and their log files on a single 2TB volume.
Thanks Paul for clarification.
One more Q this is apply on RAID Volumes also or there is different between JBOD.
For auto reseed it’s recommended to use JBOD. If you RAID your disks then the failure of one disk is not going to cause a volume to fail, so auto reseed will have nothing to do.
Thanks Paul..
Great Article!!
We are implementing an Exchange 2016 environment using 5.5Tb SATA drives ReFS as Mount Points with 4 MailDB folders under each Mount Point.
I’d like to run JetStress on the servers to verify the config.
Can/should I run JetStress using the above config?
Or should I format the drives NTFS with Drive Letters, run JetStress, then reconfig the drives as above?
You should Jetstress your intended storage configuration, not a different configuration.
Thanks Paul…
We are using physical hardware with multiple servers (including 9 6Tb SATA drives in each).
When configuring the RAID controller, is the preferred method to create each drive as a single drive with RAID0 & a 256K stripe, then create mount points? Or 1 big drive RAID0?
Do I use the RAID controller to configure the HotSpare, or will that be in the DAG setup?
Thanks again…I’m finding little pieces to this config, but nothing all together
I think you might be missing the point. JBoD is the setup for the volumes. Raid 1 or 5 the OS drive and that’s all there is to do. DAG mutes the need for redundant disks.
Correct. Leaving the 6TB drives as RAW disk doesn’t leverage the cache on the RAID controller…leading to JetStress failing miserably.
To setup a HotSpare with AutoReseed, is that done within the DAG configuration??
Should the drives be individual RAID0 (so it uses the RAID controller cache), and config DAG to see a single 6TB RAID0 ReFS drive as the HotSpare?
I thought you didn’t config RAID1 or 5 and let Exchange manage the DAG and HotSpare.
If you have RAID, then the volume is unlikely to ever completely fail, which means Autoreseed will never need to do anything. Autoreseed uses an available spare volume that it can see in Windows. It doesn’t integrate with your RAID controller or any RAID controller managed hot spare disk.
The point of Autoreseed is to not use RAID for your Exchange database/log volumes. You get more overall disk capacity to use because you aren’t losing any of it to RAID, and you get a simpler storage configuration because you’re just presenting disks as volumes instead of having to manage RAID controllers, RAID configs, monitor RAID health, rebuild RAID when a disk fails, etc etc. Microsoft’s experience with Office 365 is that most Exchange failures are caused by disk controllers or disks, hence why Autoreseed was developed to automatically recover from those.
In short, if you’re going to RAID all your Exchange database/log storage then you can pretty much ignore Autoreseed.
Unfortunately, if the 6TB SATA disks are left RAW then they dont leverage the RAID controller cache and fail JetStress. I have configured each individual 6TB SATA drive as RAID0 using a 256K block size. NOT one big 54TB RAID0 drive. The point of this was to leverage the Autoreseed funtionality.
Win2012R2 DiskMgr sees each drive as a 6TB drive and I’ve created mount points per Pauls instructions above. Leaving one drive as an empty 6TB ReFS drive. I’ll use the spare 6TB drive when configuring Autoreseed.
I guess my point is…you need to leverage the RAID controller cache with the drives or I/O latency is horrible and will fail JetStress.
Thanks for the clarification Paul
Excellent Article!
Paul – If you can add “Printer” icon to all your articles, it would be very nice.
agree 100% with the previous comment
awesome/best explanation i saw
Excellent article I have ever seen on auto reseed feature of exchange 2013. Great work, thank you Paul.