When you’re running an Exchange 2013 database availability group you will eventually need to deal with a failed database copy that needs to be reseeded.
Database copies may be in a failed state due to a variety of reasons, such as a hardware failure on the underlying storage system. After resolving the root cause of a failed database copy you then need to reseed the copy, which is a process that creates a new copy of the database by replicating the data from another DAG member that hosts a healthy copy.
To demonstrate how to reseed a failed database copy I’ve first caused a failure of one of my databases, which can be seen here in the output of the Get-MailboxDatabaseCopyStatus cmdlet.
[PS] C:\>Get-MailboxDatabaseCopyStatus * Name Status ---- ------ Mailbox Database 1E15MB1 Healthy Mailbox Database 2E15MB1 FailedAndSuspended Mailbox Database 1E15MB2 Mounted Mailbox Database 2E15MB2 Mounted
If you’re looking for guidance to resolve failed content indexes in your database availability group, see PowerShell Tip: Fix All Failed Exchange Database Content Indexes.
The reseed operation can be started using either the Exchange Admin Center or the Exchange Management Shell (PowerShell).
Preparing to Reseed a Database Copy
There are a number of considerations when reseeding a database copy.
First, the time required for the reseed to complete will depend on the size of the database and the network performance between the source and destination servers.
By default the reseed will use the DAG member hosting the active database copy as the source.
If the database is 500Gb in size, that is 500Gb of database that needs to be copied across the network, plus the transaction log files and the content index for that database. This can add up to a lot of data that needs to travel across your network.
If the DAG members exist only within a single site connected by high speed LAN then this will not likely be a concern.
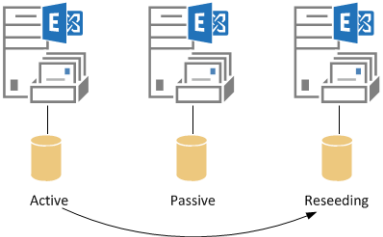
However if the DAG members exist in multiple sites across a WAN then it may be more of an issue.
Fortunately, you can specify a source server for the database reseed, which allows you to select a server that has better connectivity to reseed from, such as another DAG member within the same site as the server with the failed database copy.
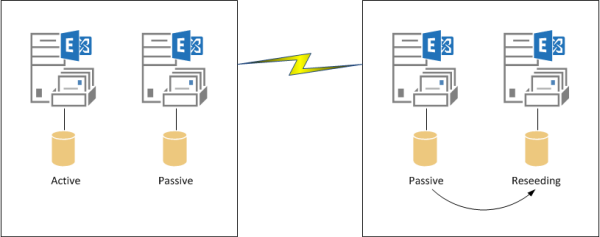
The options for selecting a reseed source will be demonstrated below.

Reseeding a Database Copy Using the Exchange Admin Center
Open the Exchange Admin Center and navigate to Servers -> Databases. Select the database that has the failed copy.

On the database copy that is shown as failed click the Update link.
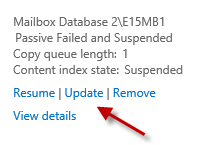
You can click Browse and specify a source server if necessary, otherwise click Save to reseed from the server that hosts the active database copy.
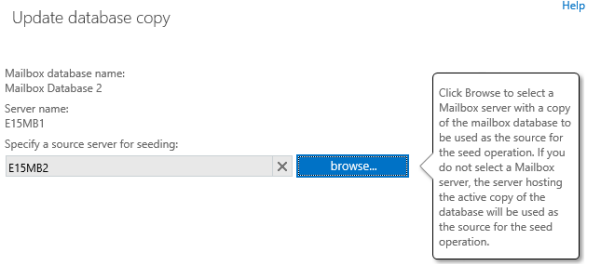
Wait for the reseed operation to complete.
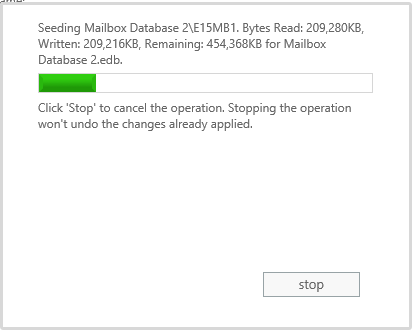
When the reseed operation has finished the database copy should now be healthy.
Reseeding a Database Copy using the Exchange Management Shell
We can also perform reseeds using the Update-MailboxDatabaseCopy cmdlet.
The database to reseed is entered in the format “Database NameServer Name”, for example:
[PS] C:\>Update-MailboxDatabaseCopy "Mailbox Database 2E15MB1"
To specify a source server for the reseed use the -SourceServer parameter as well.
[PS] C:\>Update-MailboxDatabaseCopy "Mailbox Database 2E15MB1" -SourceServer EXMB3
If you receive an error message that log files already exist in the transaction log path for the database you can use the -DeleteExistingFiles parameter to tell the Exchange server to remove those files before beginning the reseed.
[PS] C:\>Update-MailboxDatabaseCopy "Mailbox Database 2E15MB1" -DeleteExistingFiles
Finally, for long reseeds where you do not want to leave your Exchange Management Shell open, or when scripting a reseed and you don’t want the script to have to wait for the reseed to complete, you can use the -BeginSeed parameter.
[PS] C:\>Update-MailboxDatabaseCopy "Mailbox Database 2E15MB1" -BeginSeed
Of course those parameters can be used in conjunction with each other, for example:
[PS] C:\>Update-MailboxDatabaseCopy "Mailbox Database 2E15MB1" -DeleteExistingFiles -BeginSeed -SourceServer E15MB3
Monitoring Database Copy Health
If you do not already have a monitoring solution in place for your Exchange 2013 DAG I encourage you to try my Get-DAGHealth.ps1 or Test-ExchangeServerHealth.ps1 scripts.



Hi Paul, thanks for your help the reseed works as you explain, just aquestion, I have two database one 170 GB and the other 380GB. The 380 GB database reseed takes around 3 hours to finish but the 170 GB takes 26 hours more than a day, both server are in the same lan. Any idea.
Regards
Richard
You will need collect performance data, most likely disk performance stats, to narrow down the issue.
Hi Paul,
I would really appreciate your help.
I am running Exchange 2013 with 2 mailbox and 2 CAS servers and also with 3 databases. One of the database is failing replication and when I run test-replicationhealth, I get;
LNDV-EXMB01D DatabaseRedundancy *FAILED* There were database re…
LNDV-EXMB01D DatabaseAvailability *FAILED* There were database av…
I tried reseeding this 3 times and each time it is complete but as mailbox is in failed state, they start rebuilding.
Using EAC, I can see the error;
Incremental seeding of database Archive Database\LNDV-EXMB01D encountered an error. A full reseed is required. Error: The Microsoft Exchange Replication service failed to determine if the log files in database ‘Archive Database’ are divergent from the source copy on server ‘LNDV-EXMB01C.games-int.net’.
I m not sure how to run full reseeding so wold appreciate if you can explain procedure/commands.
I am also extending disk as it is running out of disk due to pending logs.
There are lots of error event logs regarding MSExchRepl (124, 3145, 106)
Not sure I understand your question. The blog post above describes how to do a “full” reseed. A reseed copies a fresh set of logs and database files to the mailbox server.
Hey Paul,
Can you run a full database reseed and perform a backup at the same time ? This is for 2010 or really any version of exchange.
Robert
Hey Paul,
On exchange 2010 if you start a database reseed and the powershell window is closed does that cancel the re-seed?
Thanks,
Robert
Not sure, I’ve never tried it and I don’t have any 2010 servers around to test with. Exchange 2016 has a -BeginSeed switch that backgrounds the task, but 2010 doesn’t.
Thanks Paul. What about the backup question, do you know if you can run a backup and a reseed at the same time? If so, might you have to manually reseed from one database copy and then backup from a different copy ?
Robert
No, you can’t backup and reseed at the same time.
Hi Paul, I have a strange issue today, I have a newly created DAG on a Exchange 2016 environment. All runs fine add-Dag member and then creating Databases.
But one Databasecopy is in stauts failed and suspended. I have tryed many times to reseed also with -deleteexistingfiles…but nothing worked for me.
I removed the copy deleted the files on the copy server and added the copy again…same failed and suspended..
Is there another trick for those behaviour? Or should i delete the db completly and make them new?
Thanks and many thanks for the great Job you doing here for all the Exchangeadmins 🙂
You should troubleshoot the problem. To start with, look at the event logs on your servers.
Hi Paul,
Just to check, like what your example shows in the article, my environment only has 2 servers in one single DAG. which one of my database is currently failed and suspended. and I have to reseed the database on my second server.
So during the reseed, will the database still be active and usable in terms of mailflow since on that database, I only have 1 active database.
Thanks in advance
If you still have an active database copy then the database will continue to be available for mail flow and end user access.
After about a week re-indexing the ContentIndex now shows healthy, it was crawling the database for almost an entire WEEK. Now I need to pull stuff out and delete it.
Hi Paul thanks for the writeup, what if both my copies are failedAndSuspended? I have no “Healthy” copy to reseed from this is our Journal and it’s over 1TB in size. The reason is we ran out of space. Wil they eventually catch up on their own or do I need to do something different?
Hi Paul,
I followed Manually Seed an Exchange 2010 DAG Database copied the DB file and take over to remote site but no luck after resume the seed getting below error any thoughts how to solve this issue?
The Microsoft Exchange Replication service encountered an error while inspecting the logs and database for Prod1DAG2 on startup. Error: File check failed : Required log file ‘D:Program FilesMicrosoftExchange ServerV14MailboxProd1E040005BDB5.log’ wasn’t found. There appears to be a gap in the range of logs required by the database. Please reseed the database copy.
Please advise how to solve this issue.
Hi Paul,
Do we have a script that can check a failed database copy then automatically reseed it.
Shouldn’t be too hard for anyone in your team familiar with PowerShell to write one. I would recommend you be careful with letting a script automatically reseed failed DB copies over and over and over again. You should set some kind of alert threshold, if it is attempting the reseed more than X times per day it should stop and alert you for manual investigation.
Paul, I am getting this odd error (at the bottom) when trying to do a reseed and I have to resort to deleting the copy altogether and recreate the entire .edb and do a full seed. Randomly databases get out of sync and this is the result. Also, this was an issue before we had any anti-virus as well as after installing anti-virus (with proper exceptions in place) so we know anti-virus isn’t the cause even though its typically is the culprit, do you have any ideas what might cause this? Perhaps Web proxy or something between the datacenters causing the DAG network not to work or stop unexpectedly? Other databases on the same 2 mailbox servers stay in sync so I’m at a loss.
The seeding operation failed. Error: An error occurred while performing the seed operation. Error: An error occurred while communicating with server “server name”. Error: Unable to read data from the transport connection: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond. [Database: “database name” – Server: “server name”]
Is there a way to seed a database using a restored backup from another server?
This would allow us to overcome some WAN issues slowing down initial seeding.
Any thoughts?
Cheers
Ray
You should read this:
http://blogs.technet.com/b/timmcmic/archive/2011/07/12/exchange-2010-using-vss-to-perform-an-online-offline-database-seed.aspx
Thanks Paul. Knew it was there somewhere but obviously didn’t Google hard enough.
Ray
Hi Paul
i have on my Exchange 2013 dag the following message :
Passive Healthy
Copy queue length: 0
Content index state: FailedAndSuspended
What do you recommend?
i have already tried
Get-MailboxDatabaseCopyStatus * | where {$_.ContentIndexState -eq “Failed”} | Update-MailboxDatabaseCopy -CatalogOnly
with no result
Thank you for your time
Dear Paul,
Just one small question about reseeding.
In an environment with 4 DB copies (1 active, 2 passive, 1 lagged copy) if there is e.g. a disk failure and we need to reseed the DB to the new disk, which copy can we should we use as source? Should we seed from the active DB or the passive?
We have local attached storage with JBoD disks configured.
Best regards,
Szabolcs
Any of the non-lagged copies can be used as the seeding source. If the DAG stretches across multiple sites I tend to choose a database copy closest to the server I am reseeding to.
Thanks Paul! You have confirmed my assumption for me.
Pingback: RESEEDING THE DAG | Technical Reference
Pingback: How to Install and Configure Exchange 2013 with PowerShell - Exchange and SCOM Site
Pingback: Information About China And Hong Kong Wikipedia
Pingback: Exchange Server 2013 Database Availability Groups | Hisham Mezher
Seems like our remote Database over the WAN crashes much more often and reseeding it is a huge undertaking because the DB is so big, takes about a week.
What are some of the causes of this? In the event viewer I get a bunch of corrupt log errors.
At ‘1/31/2014 5:15:48 AM’ the Microsoft Exchange Information Store Database ‘LWGDB01’ copy on this server encountered a serious I/O error. A lost write was detected. Consult the event log on the server for “ExchangeStoreDb” or “MSExchangeRepl” events that may contain more specific information about the failure.
Information Store – LWGDB01 (5092) LWGDB01: Database E:LWGDB01LWGDB01.edb: Page 5675453 (0x005699bd) failed verification due to a timestamp mismatch. The ‘before’ timestamp persisted to the log record was 0x177b4100 but the actual timestamp on the page was 0x177b4082. The ‘after’ update timestamp 0x177b4101 that would have updated the on page timestamp. Recovery/restore will fail with error -566. If this condition persists then please restore the database from a previous backup. This problem is likely due to faulty hardware “losing” one or more flushes on this page sometime in the past. Please contact your hardware vendor for further assistance diagnosing the problem.
I ran a eseutil /r /l E00 F:logdatabase. It fixed my time and said I had no logs required. However, the database in the DAG is still suspended. Is there a way to bring it back online without reseeding?
The State now shows Clean Shutdown as before I ran that command it said dirty shutdown.
You can resume a suspended database copy. If it keeps suspending itself automatically that indicates a problem, and there’ll be event log entries explaining why it was suspended. Often the situation involves a full reseed for a database copy that is too far out of sync with the other copies.
Storage hardware issue perhaps. Sounds pretty messy and worth opening support calls with Microsoft or your storage vendor (or both).
If you want to minimise reseed times use smaller databases (ie break up a large database into multiple smaller databases).
Pingback: Exchange Server 2013 Database Availability Groups
Hi Paul,
I had no intention of having you do my google’ing for me but thank you for the link 🙂
I will be sure to look into the server maintenance mode scripts.
Thanks for the further explanation in the link below.
https://www.practical365.com/bother-running-dag-server-maintenance-mode-scripts/
Take it easy.
Hi Paul,
I have a fairly new 2013 Exchange setup. I have noticed the following after rebooting one of the DAG members and was wondering if this behavior is expected, in particular the copy queue length? The server that was rebooted has the passive copy and the copy queue length was at 0 before the reboot but now it’s huge. I had a similar instance with the other DAG member when I rebooted it, the only difference was the contentindexstate was in a failed status. I tried updating only the catalog per one of your docs but it continued to stay in a failed state. After about 24 of no intervention on my part it fixed itself. Just trying to find out if the symptoms here are expected or if I have bigger issues.
Thanks as always for sharing your knowledge. Your documentation has saved me on several occasions!
Identity : mailboxmyserver1
Id : mailboxmyserver1
Name : mailboxmyserver1
DatabaseName : mailboxmyserver1
Status : Healthy
LastStatusTransitionTime : 10/23/2013 3:15:07 PM
MailboxServer : myserver1
ActiveDatabaseCopy :myserver2
ActiveCopy : False
ActivationPreference : 2
StatusRetrievedTime : 10/23/2013 3:17:09 PM
WorkerProcessId : 8004
ActivationSuspended : False
ActionInitiator : Service
ErrorMessage : The timestamp indicating the age of the last log generated on the active
database copy is ’10/23/2013 3:16:54 PM’, which is stale or missing. As a
safeguard, the system set the copy queue length to a large value to prevent
losses greater than the automatic database mount dial setting.
ErrorEventId :
ExtendedErrorInfo :
SuspendComment :
RequiredLogsPresent :
SinglePageRestore : 0
ContentIndexState : Healthy
ContentIndexErrorMessage :
ContentIndexBacklog : 0
ContentIndexRetryQueueSize : 0
ContentIndexMailboxesToCrawl :
ContentIndexSeedingPercent :
ContentIndexSeedingSource :
CopyQueueLength : 9223372036854501780
ReplayQueueLength : 35
ReplaySuspended : False
LatestAvailableLogTime : 10/23/2013 10:14:37 AM
LastCopyNotificationedLogTime : 10/23/2013 10:14:37 AM
LastCopiedLogTime : 10/23/2013 10:14:37 AM
LastInspectedLogTime : 10/23/2013 10:14:37 AM
LastReplayedLogTime : 10/23/2013 9:25:56 AM
LastLogGenerated : 9223372036854775807
Long answer:
http://blogs.technet.com/b/timmcmic/archive/2012/05/30/exchange-2010-the-mystery-of-the-9223372036854775766-copy-queue.aspx
When you’re rebooting the server I hope you’re putting it in DAG maintenance mode first?