This article is the first in a series of articles for Systems Engineers that want to develop skills to manage their code.
Code is No Longer Just for Developers
For tenant administrators, Service Reliability Engineers, and IT Professionals, code plays a larger role in the work we do year after year. Whether it is PowerShell, Terraform, JSON, XML, Markdown, or even good old batch files, we interact with code nearly every day.
Here, on practical365.com, there are dozens of scripts that authors have written that many people have used. Here are just a couple within the last month:
How to Report Meeting Statistics for Room Mailboxes (practical365.com)
As the amount of code we deal with increases, we must develop new skills and adopt tools to help us manage our source code.
Developers have managed code for decades. A variety of tools are available, such as Microsoft Team Foundation Server, Mercurial, Subversion, and dozens more. These tools all fall under the category of Source Control. Source control enables multiple people to edit the same code base in an organized manner and keep track of all changes that have been made. This is extremely helpful, even if you only have one other person editing scripts.
Benefits of Source Control
- You don’t have to use filenames to manage different versions. If you have ever written a script longer than 10 lines, there is a good chance you have had a directory with a file listing like the one below:
- MyScript.ps1
- MyScript.ps1.bak
- MyScript.Final.ps1
- MyScript.Final.2.ps1
- MyScript.Final.ReallyFinal.ps1
- MyScript.Final.ReallyFinal.v2.ps1
- Source control makes you think about what you are changing and why. You will see later in the article that you can commit changes with a message tied to the change. Was it a bug you fixed? Was it a new feature? These capabilities make it easy to see a history of what has changed over time.
- As you and your colleagues create and maintain more and more scripts, source control can enable your team to manage all your scripts, to know what version is the latest, and what changes were made.
Why Should we use Git for Source Control?
If a new project starts up today that requires source control, it is highly likely that it will use Git. This answer on Stack Exchange’s Software Engineering site has some interesting data and trends of which tools have been used over the years.
Git was created in 2005 by the Linux development community, mostly by Linus Torvalds himself, to manage the source code for the Linux kernel. Git can scale from one person managing a few scripts to well over a thousand contributors working on the Linux kernel.
As described on https://git-scm.com, “Git is a free and open-source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.”
Learning Git is an investment. It will take time. It is not intuitive when you first start. However, it is absolutely worth it. If you write PowerShell code today, do you remember the first time you opened the shell and tried to understand how the pipeline worked? You eventually got comfortable with it, but it took time. Just like PowerShell, Git is an incredibly powerful asset that will reap long-term benefits for your career as an IT Professional.
How Git Works
As I mentioned above, learning Git is an investment. It is my opinion that when you begin to learn Git, you should use the Git command line tool. There are dozens of tools, GUIs, and Integrated Development Environments (IDEs) that work well with Git, and you should absolutely start to use them once you master the basics. However, when you are learning, I think it is best to use the raw command line. This will help you understand what is really happening and even how some of the tools work under the hood. If you use a tool that executes a bunch of commands because you clicked a button, good luck troubleshooting it if something goes wrong. Yes, the command-line interface will take more time. But it is absolutely worth the extra time.
Git starts pretty simple. You can make any directory on your computer a Git repository and start tracking changes to files. Git adds a hidden folder in that directory that stores your entire git history and all your changes. You can use Git on your local system and never have to push it up to a repository like Github.com or Azure DevOps.
One way to think about Git is that it divides the directory on your filesystem into three virtual “areas.” You use Git to add and remove files from these three areas depicted below (Figure 1):
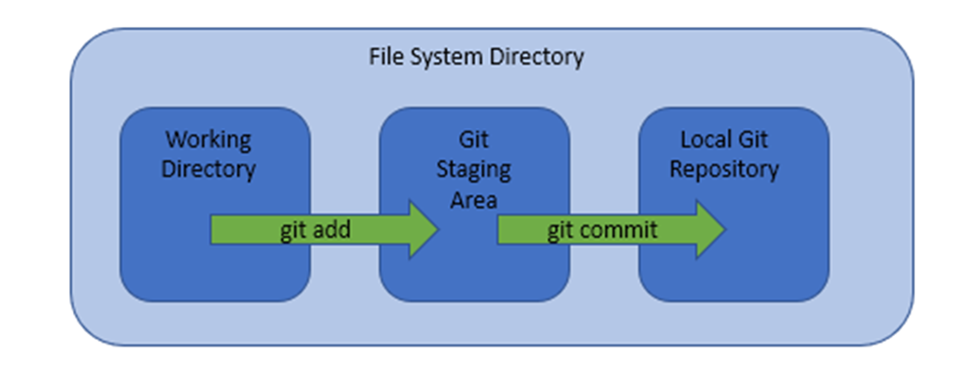
When you create a new file, it goes into the working directory. The command “git add” is used to add the file or files to the git staging area. When you are ready to commit the changes, the command “git commit” is used to commit the file from the staging area to the local repository.
Every time you commit new files or make changes to files, git stores that “version” of all the files in the repository. It is marked with a hash. You can always go back to that version.
Let’s Git Started
First and foremost, you can download and install Git here. It is also available on many package managers like Chocolatey for Windows or Homebrew on Mac and Linux. This is all you need to start using Git.
This demo uses PowerShell. The git commands will all be the same, but feel free to use whatever shell you feel comfortable using to create directories and update files.
Create a new directory, and switch to it. Then, create a new file with some text.
md gitDemo && cd gitDemo Add-Content "File1.txt" -value "one line in file1"
We have a new directory with a file but no source control. Turn this directory into a Git repository by initializing it. Note the use of the period at the end of the command. This means initializing the repository in the directory we are currently in.
git init .
Let’s see what the status of our Git repository is. It should show one file that is not being tracked, which is the File1.txt file you created earlier.
git status
We can start tracking the file and add it to the staging area using the git add command. Here you can either use Git add . or Git add filename. Git add . will add all files and updates to the staging area. This is a useful shortcut, but you should remember that you can add files individually. Maybe you created a bunch of new files, but you only want one file added to the next commit you are making.
git add .
If you run Git status again, you will see that the new file is added and is ready to be committed.
git status
Now we can commit the file to the repository. Rather than simply running Git commit, we must also supply a commit message. This message will help identify what was done on this commit. This can be very useful a month or two down the road when you review the history of your commits to see what changes were made.
git commit -m "This is the initial commit for this repository"
Let’s make one more change, add the change to staging, and then commit the change.
Add-Content "File1.txt" -value "one more line in file1" git add . git status git commit -m "Added a second line to file1" git status
That last status command should show that everything is clean and that there is nothing to commit. There is one last command we will try so that you can see the history of your commits.
git log
The Git log command will list out the commit ID, or the hash of the commit, the author, date, and the message you specified when you made the commit.
A Quick Note on Committing and Commit Messages
I strongly suggest committing small units of work and using commit messages that make sense. The commit itself should also be a small unit of work that can easily be described in a single-sentence commit message, such as “Fix bug when the username is null” or “Update script to use Modern auth instead of basic authentication.”
When you write a commit message, think about what you would need it to say if you were reading it 6 months from now, or if someone else reads the message. It should be clear and concise.
Git Started Today
If you are not using Source Control today, it’s a great day to get started. Yes, Git is a large and complex ecosystem. You can start small. The investment you make in learning Git will become a great asset for your career.
Cybersecurity Risk Management for Active Directory
Discover how to prevent and recover from AD attacks through these Cybersecurity Risk Management Solutions.



Thanks for this article. I’m a “classical” system administrator and now confronted with the field of devops. What to do with this and how can I benefit from this technology for my daily operations? Even though I don’t code and our company doesn’t produce software.
Thanks! Would be great to here you‘re thoughts on how to organize a repository and how you would manage configurations, and change management.
Hi K365, Be on the lookout for the next article in the series. I will be discussing repo organization, particularly for when you have more than one contributor.