I’ve received a number of questions lately from people who are concerned about database failover behaviour in their Exchange Server environment.
The scenario is usually that a failure has occurred, and the active database copy moved to a server that they were not expecting it to move to.
Their expectations are based on the activation preference they have configured on their database copies. Basically they expected the database copy with AP=2 to become active, but instead the database copy with AP=3 or AP=4 became active.
The issue here is a misunderstanding about how activation preference works. AP is an administrator-assigned preference for the order in which database copies should become active, but it is not a hard and fast rule.
Instead, “targetless” database switchovers/failovers (ie, *-overs in which an administrator has not explicitly specified which database copy should become active) involve a process called “best copy selection” to determine which database copy becomes active.
Let’s take a look at a simple example. In this scenario there are four database availability group members across two datacenters. The Exchange administrator has configured the database copies in datacenter 1 to have AP=1 and AP=2, because that is the datacenter in which they prefer the database copies to be active.
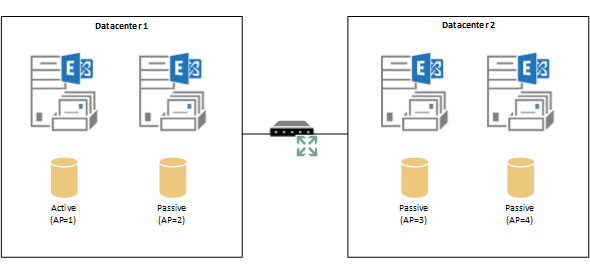
Some problem occurs on the server hosting the active database copy causing it to dismount, and the Primary Active Manager (PAM) begins the best copy selection process.
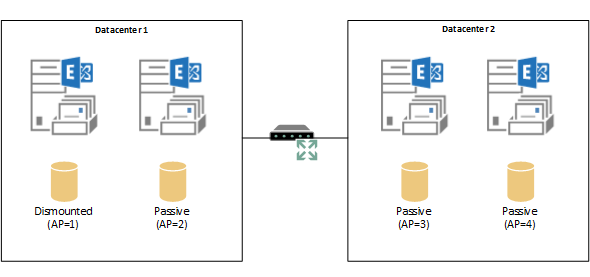
Best Copy Selection
Best copy selection is a complex process involving a number of variables that are assessed by the DAG so that a database copy can be chosen to become active to restore availability of service, while balancing that objective against the risk of data loss if a database copy that is not fully up to date with the latest changes was made active.
Database copies that are considered failover candidates are sorted depending on a number of variables.
The first is the AutoDatabaseMountDial setting, which is configured on each Mailbox server in the DAG. This setting configures the threshold for the number of missing log files (or the copy queue length) for the database copy for it to be considered unmountable. There are three possible settings:
- GoodAvailability – this is the default setting and allows a database copy to be automatically mounted if it has a copy queue length of six or less.
- BestAvailability – allows a database copy to be automatically mounted if it has a copy queue length of 12 or less.
- Lossless – allows a database copy to be automatically mounted only if there are no missing log files.
Note: It may seem like “Lossless” is the only logical choice here, because who would willingly choose an option that may result in data loss? However it is often better to allow service to be restored by mounting a database copy that has some missing log files, and then data loss can be mitigated by other means such as by requesting email messages to be resubmitted from Safety Net.
Here is where activation preference comes into play:
- When AutoDatabaseMountDial is set to Lossless on any of the Mailbox servers hosting a copy of the database, the failover candidates are sorted in ascending order of activation preference.
- When AutoDatabaseMountDial is set to GoodAvailability or BestAvailability, the failover candidates are sorted by their copy queue length, in order of shortest to longest. If two database copies have the same copy queue length then the activation preference is used as the tie breaker.
Note: The recommended practice is to set the AutoDatabaseMountDial to the same value for all servers within the DAG.
At this stage in the process even database copies that have missing log files in excess of the AutoDatabaseMountDial threshold are still in consideration as a potential activation candidate, because a process called “attempt copy last logs” (ACLL) will run to try and copy the missing log files from the server that last hosted the active database copy before the failure occurred.
ACLL is useful in situations where the failure is not a total server failure, and the log files are still accessible, which allows a passive database copy that may be excluded from consideration as a failover candidate due to missing log files to copy the missing files and therefore get itself back into consideration.
However, before ACLL runs the best copy selection process needs to choose a database copy to be the candidate to become the active database copy. For that to occur a series of checks is performed on the activation candidates, that includes the following characteristics:
- Copy queue length – the number of transaction log files yet to be shipped from the server hosting the active database copy
- Replay queue length – the number of transaction log files that have been shipped to the passive copy’s server but have not yet been replayed into the passive database copy
- Database status – such as “Healthy” or “Failed”, among other possible values
- Content index status – such as “Healthy” or “Failed”, among other possible values
In Exchange Server 2013 the process is now called “best copy and server selection” (BCSS) because it also takes into account the health of other server components thanks to Managed Availability. This is a significant improvement because, of course, there is little gain to be had from failing over a database to a Mailbox server that has a client protocol in an unhealthy state if there are other more healthy servers to choose from.
You can read more about BCS for Exchange 2010 and BCSS for Exchange 2013 on TechNet, which also includes some example scenarios, but let’s go back to our simple example scenario here for now. For the sake of ease I will use the acronym BCS to refer to both versions of Exchange.
Assuming in this failure scenario that the AutoDatabaseMountDial is set to the default value of GoodAvailability, and that all other server components are equally healthy.
If all three database copies are healthy, have an equal copy queue length of 0, and have healthy content indexes, then the activation preference is used as a tie breaker and the copy with the lowest AP value will be mounted. With this result the administrator is happy that database failover has adhered to their preferences.
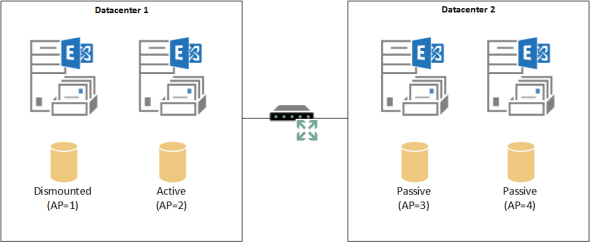
However, if the database copy with AP=2 has a copy queue length higher than the others (which is quite possible even under normal healthy conditions), when the failover candidates are sorted based on copy queue length it will not be the first candidate for mounting. In this situation the database copy with AP=3 may mount instead.


What if You Don’t Want a Database Copy to Become Active?
Is this best copy selection behaviour a bad thing?
Well, from the perspective of wanting the most viable database copy to become active in a failover situation, no it is not a bad thing. In fact, considering the architectural changes in Exchange Server 2013, it may be preferable to allow this type of failover scenario to occur in the interests of high availability.
However, I appreciate that in some Exchange Server environments it may not be desirable for databases to failover unexpectedly to a different datacenter.
An AutoDatabaseMountDial setting of Lossless isn’t the answer because even though it causes BCS to sort the database copies in order of activation preference, if the next database copy is missing even a single log file then it won’t be considered mountable.
Instead, we can block database copies from activating using one of two methods.
To block a specific database copy from activating we can use Suspend-MailboxDatabaseCopy with the -ActivationOnly switch.
[PS] C:\>Suspend-MailboxDatabaseCopy DB1E15MB3 -ActivationOnly
To block an entire Mailbox server from activating database copies we can set the DatabaseCopyAutoActivationPolicy for the server.
[PS] C:\>Set-MailboxServer E15MB3 -DatabaseCopyAutoActivationPolicy Blocked
Why Do You Flag Activation Preference as a Warning in Your Scripts Then?
If you’ve used my Test-ExchangeServerHealth.ps1 or Get-DAGHealth.ps1 PowerShell scripts then you may be wondering why I chose to flag a warning if a database is active on a copy other than the copy with AP=1.
The reason is that many Exchange administrators were telling me about their problems with unexpected database failovers, specifically that they wanted to know when failovers had occurred so that they could troubleshoot the root causes and make sure that, for example, a failed database copy doesn’t sit unnoticed for days at a time.
Which is fair enough. If you don’t have a monitoring system telling you about database failovers, and the end users aren’t complaining, then you run the risk of your DAG health slowly degrading until all of a sudden a database goes offline and you discover you’ve got no healthy copies to mount.
What Else is Activation Preference Useful For?
Since activation preference is only one of many factors in BCS you might be wondering whether they are useful for anything else.
The answer is yes, they are useful when you are rebalancing your DAG using the RedistributeActiveDatabases.ps1 script that ships with Exchange Server 2010 and 2013.

Summary
Best copy selection runs every time a “targetless” database switchover or failover occurs within the database availability group.
For a lot of environments the DAG is healthy enough that the database copy that is next in order of activation preference will mount, because the activation preference value was used as a tie breaker between multiple database copies with equal copy queue lengths (often 1 or 0 in a healthy environment). This is why many administrators simply assume that activation preference is the sole determining factor for which database copy becomes active in a failover scenario.
However as you can see above, it is important to be aware that activation preference is not a hard and fast rule, and that BCS may mount other database copies instead of the next one in order of AP if it finds one that is a better candidate.



after update one node of exchange 2019 i cant move database mounted this server and event id error is 806
Database ‘Mail01’ best copy could not be found. Details: ‘server name ‘: 0x614324, number of passives: 0, constraint: SecondCopy.
in event viewer see another error:
Passive BlockMode for database ‘Mail01’ failed to read data. Active was server name node 2 . Error: Microsoft.Exchange.Cluster.Replay.NetworkCommunicationException: An error occurred while communicating with server ‘server name node 2 ‘. Error: Unable to read data from the transport connection: An existing connection was forcibly closed by the remote host. —> System.IO.IOException: Unable to read data from the transport connection: An existing connection was forcibly closed by the remote host. —> System.Net.Sockets.SocketException: An existing connection was forcibly closed by the remote host
at System.Net.Sockets.Socket.EndReceive(IAsyncResult asyncResult)
at System.Net.Sockets.NetworkStream.EndRead(IAsyncResult asyncResult)
— End of inner exception stack trace —
at System.Net.Security.NegotiateStream.EndRead(IAsyncResult asyncResult)
at Microsoft.Exchange.Cluster.Replay.NetworkPackagingLayer.ReadCallback(IAsyncResult ar)
— End of inner exception stack trace —.
can you help me?
Well Explained Mr.Paul!!!
Pingback: Get-MailboxDatabaseCopyStatus Displays Wrong AP Value
Pingback: Exchange Server 2013 Lagged Database Copies In Action
Your explanations are always exactly what I am looking for – spot on with this one. Thank you!
Thanks for the article. Simple, to the point and clear.
Thanks for the explanation! Clear and to the point!
Good Article to clear assumptions of Exchange Administrators
Thank you for such a clear explanation
thanks for the nice explanation..
what we have to do in case we want to activate DR site and we already run the command..
Set-MailboxServer E15MB3 -DatabaseCopyAutoActivationPolicy Blocked
should we run
Set-MailboxServer E15MB3 -DatabaseCopyAutoActivationPolicy unrestricted
and then do the rest of command to activate the DR site ?
Regards