Using Machine Learning to Understand Documents
The process to create custom trainable classifiers for use in Microsoft 365 compliance is straightforward:
- Define the kind of information you want the trainable classifier to recognize. For example, you might want to create a trainable classifier which recognizes financial reports in a specific format.
- Assemble a set of sample documents for the training process to scan and build a digital picture using machine learning. The set acts as seed content for the classifier and should include between 50 and 500 “positive” samples available in a SharePoint Online site. In other words, by analyzing the seed content, the classifier builds a prediction model (the digital picture) to allow it to recognize documents of the same type when it processes them in future. The more representative the seed content is of real-life documents, the more accurate the prediction model is likely to be.
- Test the classifier to see how it performs when it processes real content and tweak if necessary. The seed set might require a refresh to introduce new examples to help the classifier refine its prediction model. During this phase, compliance administrators help the refining process by marking files identified by the classifier as good or bad matches. The aim is to increase the percentage of good matches to as close to 100% as possible.
- Publish the classifier to make it available for use with Microsoft 365 compliance.
- Retrain the model by giving feedback on its matches (see below).
It’s possible that a new trainable classifier will appear accurate until it starts working in compliance policies. For this reason, you should deploy new trainable classifiers in limited circumstances (for example, in an auto-label retention policy covering a small number of SharePoint Online sites) to make sure that the classifier works as intended. If it doesn’t, and feedback with bad and good matches don’t improve the prediction model over time, you might need to delete the classifier and start the training process again. If this happens, use a different set of sample documents, including examples where the previous iteration of the classifier did not detect content accurately.

Machine Learning Takes Time
Microsoft uses machine learning to create models extensively inside Microsoft 365. The document understanding model in SharePoint Syntex is like a trainable classifier in some respects. Other models include those used to predict text to insert when composing messages in OWA and Teams. In all cases, learning takes time and patience. You don’t control how Microsoft 365 operates to build and refine the prediction model. All you can do is deliver the best possible set of seed content and wait for the model to complete its processing. And then maybe wait again for a few more days. Eventually, a high-quality trainable classifier should be ready for use to:
- Find content and apply retention labels to in an auto-label policy.
- Find content and apply sensitivity labels to in an auto-label policy.
- Check for sensitive content in a data loss prevention (DLP) policy.
- Find information in the Content explorer in the Microsoft 365 compliance center.
- Check employee messages with communications compliance policies.
Perhaps because their effect is more obvious to users in terms of the presence of labels or blocks imposed on external sharing, trainable classifiers work best for Office documents stored in SharePoint Online and OneDrive for Business. However, they also work with Exchange Online for auto-label policies.
Like anything which automates an aspect of compliance, trainable qualifiers require Office 365 E5 or Microsoft 365 E5 compliance licenses.
Improving Prediction Models
Even accurate models can improve over time through validation and checking of their results. Two years ago, I created a trainable classifier based on customer invoices and used it to make sure invoices receive an appropriate retention label through an auto-label retention policy. The policy and the classifier have hummed away in the background since, and I paid them little attention. In the meantime, Microsoft enlarged the set of built-in trainable classifiers and expanded the language coverage from the initial state (U.S. English only) to cover French, Spanish, Portuguese, German, Japanese, and Simplified Chinese. Developing a classifier like Profanity involves assembling large quantities of samples of the kind of thing you want to detect, like swear words.
You can check the effectiveness of a trainable classifier by examining items the classifier considers are a match. Because of Microsoft’s activity in this area, I looked at the matching items for the profanity classifier and discovered that all matching items were in Exchange Online mailboxes. Diving deeper, you can look at items found in each mailbox to figure out why the classifier considered an item to match. In Figure 1, we see that the message content contains “WTF” and “pisses me off.” Both terms are mildly profane, but enough to match the classifier.
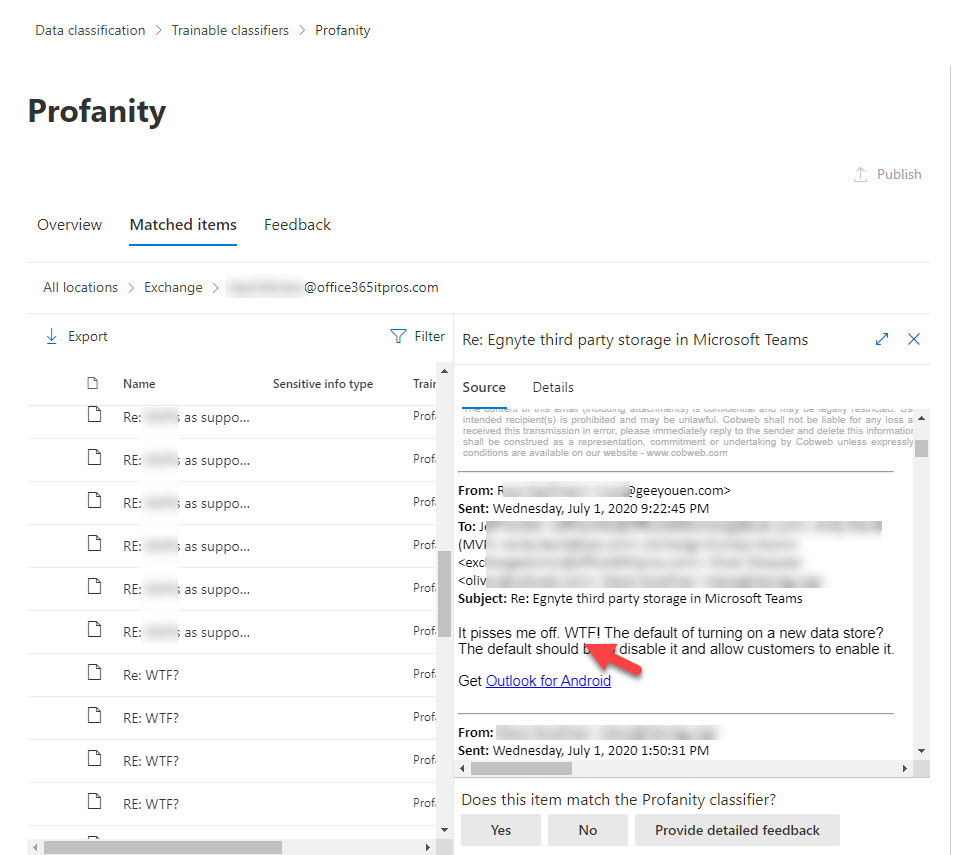
The important thing is that you can send feedback to improve the model. I can’t find an explicit statement that feedback flows to Microsoft, but given that they maintain the built-in classifiers, this makes sense.
Looking through matched items for built-in classifiers prompted me to check what matching the compliance center recorded for my Customer Billing classifier. The first batch of items (Figure 2) were fine. All the items detected by the classifier were accurate and received the right retention label, so I was happy to confirm that these matches are good. In this case, because this is a custom trainable classifier, the learning model uses any feedback submitted by compliance administrators to tweak its processing and no data goes to Microsoft.
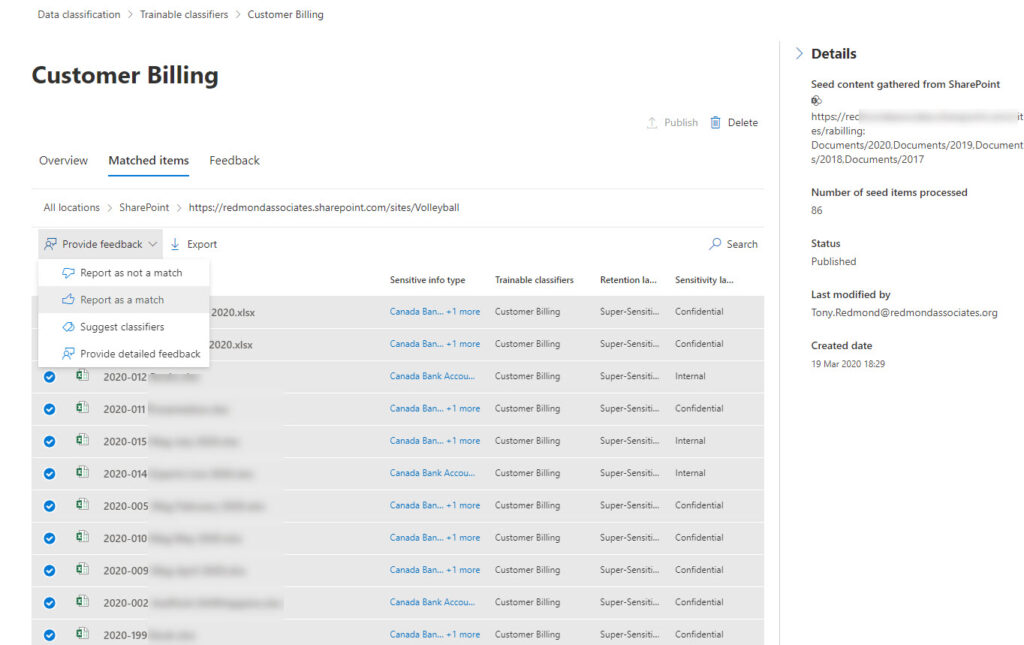
Compliance administrators can only provide feedback when a trainable classifier is in active use. In other words, it needs to be in use in a compliance policy to detect content. If the classifier is passive (unused), its predictive model is inert, and feedback will never be taken into account.
Odd Matches
I noticed that some matches existed in OneDrive for Business. This set an immediate red flag because I know that customer invoices are nor present in OneDrive (I’m the only one who generates these documents). Looking at the results displayed by the compliance center, there’s no logic for the reported matches. Instead of customer invoices, every folder in my OneDrive account shows up as a match (Figure 3). Some other Excel spreadsheets were in the reported set too, but none of these were good matches either.
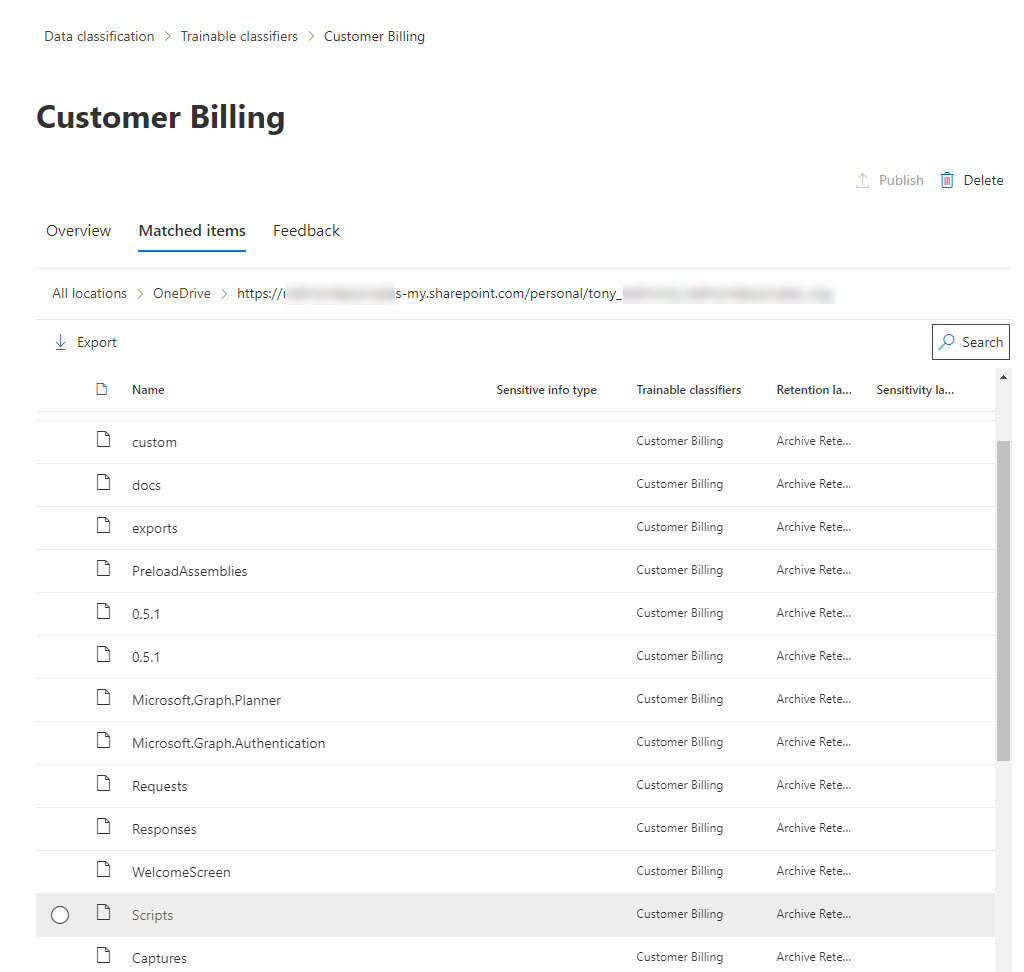
In this situation, the only thing to do is to select the bad matches and report them as not a match. The trainable qualifier uses the “not a match” feedback to avoid making the same mistake in the future. Retraining of a classifier happens automatically after the receipt of 30 or more feedback responses. The outcome is an adjusted prediction model which takes the feedback into account.

Exploring the Black Box
As noted above, it takes time before tweaks to trainable classifiers take effect. The same is true for other aspects of Microsoft 365 compliance, like auto-label retention policies. Putting the two together is like stuffing everything into a black box and hoping that everything will turn out right in the end. All you can do is observe the outcomes of the changes, by checking whether appropriate label actions occur when the classifier detects content. You can do this manually by checking labels on items in sites, by running PowerShell to analyze audit events, or by using the Activity explorer in the Data classification section of the Microsoft 365 compliance center to look for auto-applied retention label events.
Figure 4 is the Activity explorer displaying details of the auto-application of a retention label due to a match by the trainable classifier (the classifier name is not present, but the policy applies the label shown and the target document is the right type, so I call this a win).
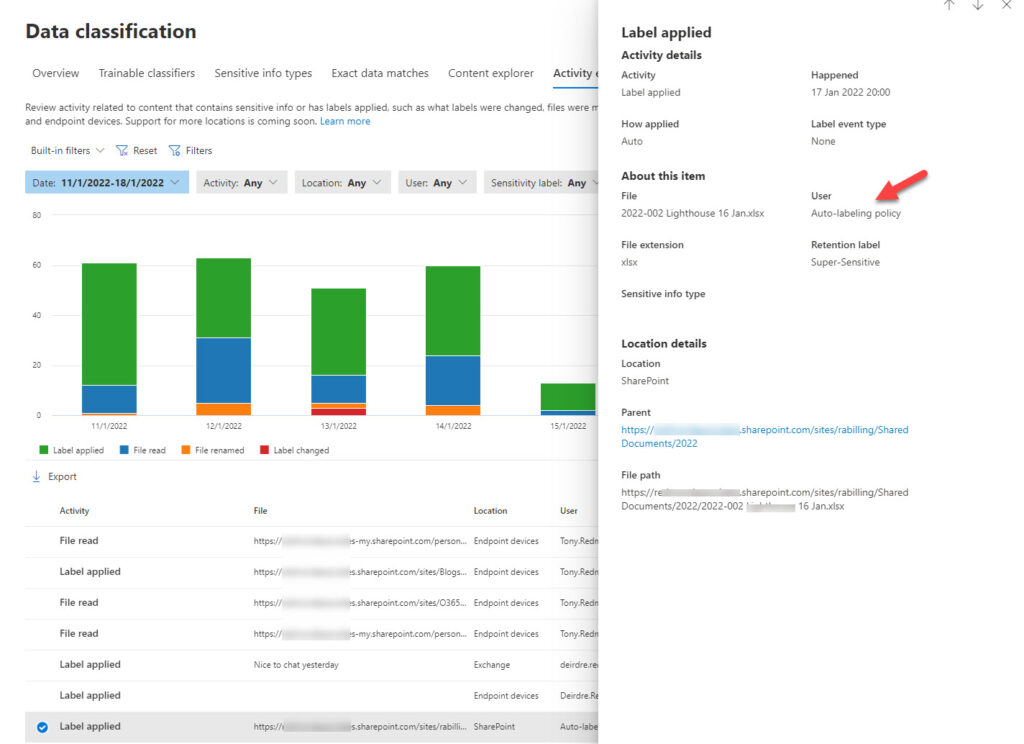
In this instance, it’s reasonably easy to see that everything is working as expected. However, Microsoft should address the lack of information available in the Microsoft 365 compliance center about trainable classifiers. For example, when you view details of a trainable classifier, you don’t see anything to say when the last update for the prediction model occurred. Viewing the matched items for a classifier tells you about the latest matches, but not what they matched against (i.e., did the model include the latest feedback).
The overview of classifiers gives an accuracy figure for custom trainable classifiers (98%, in this case), but doesn’t say anything about how Microsoft 365 calculates the accuracy or what to do to improve. In passing, Microsoft built-in classifiers don’t cite their accuracy, implying that they’re all 100% (which is not possible in the real world).
Machine Learning for All
Trainable classifiers are an interesting application of machine learning. Once you understand what’s going on, you can track the progress of policies which use classifiers and see matched items. Everything else is an impenetrable black box. We don’t expect that magicians should reveal details of their tricks, but it would be nice if Microsoft exposed more about how trainable qualifiers work. In the spirit of transparency, of course!



Hi Tony –
Do you know if it is possible to use the Microsoft Information protection scanner (for on-premises) to generate reports on Trainable Classifiers? Or does the MPIP scanner only report on Sensitive Info Types? Not seeing anything specific to that in the documentation.
Thank you
To be truthful, I have not gone looking for how to generate reports about trainable classifiers.
Thanks anyway, appreciate the response.
I have seen cases where the same document is matched to more than one trainable classifier – similar to what can happen with sensitive information types. If that can happen, then using trainable classifiers to apply retention labels becomes problematic without working out some other criteria. Is it possible to expose the trainable classifier match to KQL queries so that can be dealt with in an auto-apply policy?
Could you give an example scenario so that I know exactly what you’re thinking about?
In this case, I’m looking at documents that are matching the preview ‘Agreements’ and ‘IP’ classifiers. There are numerous documents I’m seeing in data classification where the documents match more than one of the OOB classifiers. I was hoping to use the classifiers to apply retention labels, but if I’m unable to sort out a way to prioritize the classifications, then I’m not sure which of those two classifiers associated label policies would be applied.
It’s a good question. According to Microsoft documentation: After content is labeled by using an auto-apply label policy, the applied label can’t be automatically removed or changed by changing the content or the policy, or by a new auto-apply label policy. For more information, see Only one retention label at a time.
This means that the first auto-label policy to process content gets to label it. You can’t control what that auto-label policy is. I’ll ask Microsoft about this issue. No guarantee when they might respond…
The answer from Microsoft is whatever policy gets to label an item wins. For now, policies won’t overwrite labels if they exist on items. Microsoft is considering if they can allow this to happen (and how) in the future. My response was that maybe a rewrite is possible if:
a) the label is a higher priority than the assigned label.
b) a policy setting allows the policy to overwrite assigned labels.
We’ll see what happens…