This week Amazon Web Services announced that they have added Server Name Indication (SNI) support to their Route 53 health check features.
Route 53 is an excellent DNS host. I use it myself, and generally recommend it to customers, especially when they are hosting their DNS on whatever free DNS hosting came with their domain name registration. The AWS Route 53 console is easier to work with than many DNS control panels, has none of the bugs I’ve encountered with other DNS hosts, and the service itself is fast and resilient, as well as being inexpensive to use. You can also register domains with Route 53, but you don’t need to have your domain registered or even hosted with Route 53 to make use of the health checks. If you do host your domain with Route 53, you can do some useful things like fail over the DNS records for your Exchange services from a primary site to a secondary site based on the health check status.
There are other great DNS hosts out there that have similar reliability and features, but this is not an article about DNS hosting. Instead, I want to talk about using Route 53 health checks to monitor your Exchange Server health.
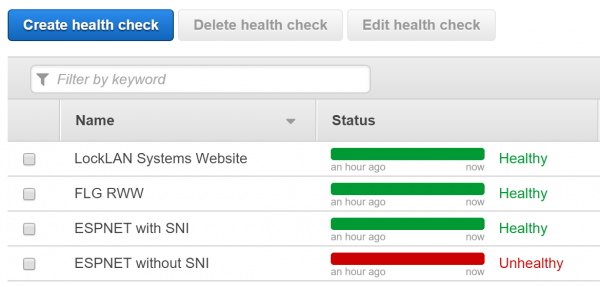
The reason that this has bubbled back to the surface for me is because previously I was not able to use Route 53 due to the lack of SNI support. I host a test lab behind a Kemp load balancer and have SNI enabled because it is handling Exchange as well as AD FS traffic. Now that SNI support is in Route 53, the health checks work. As you can see here, without SNI enabled on the health check, the server is incorrectly marked as unhealthy.
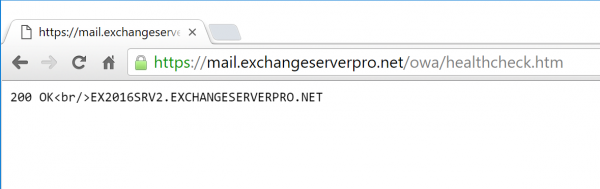
For Exchange Server 2013 and 2016 we can monitor each Exchange service independently by requesting /healthcheck.htm in the virtual directory for each service. The healthcheck.htm file does not exist, but rather is generated by Managed Availability to indicate whether the protocol is healthy or not. You can see this in your web browser by navigating to one of your Exchange services, such as OWA. For example, my test lab OWA health check URL is https://mail.exchangeserverpro.net/owa/healthcheck.htm.
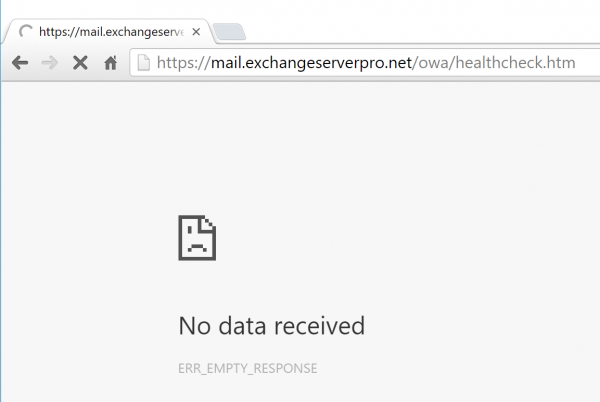
If I take the OWA components offline, the same URL doesn’t return the “200 OK” response, and the protocol can therefore be considered unhealthy by anything that is performing a health check.
[PS] C:\>Set-ServerComponentState -Identity EX2016SRV1 -Component OwaProxy -State Inactive -Requester Maintenance [PS] C:\>Set-ServerComponentState -Identity EX2016SRV2 -Component OwaProxy -State Inactive -Requester Maintenance
In total, there are 8 services that potentially need health checking. You can decide which are the most important to you if you want to monitor only a few of them.
- Outlook Anywhere (aka RPC over HTTP) – /rpc
- MAPI/HTTP – /mapi
- Outlook Web App (aka Outlook on the web) /owa
- Exchange Control Panel – /ecp
- Exchange ActiveSync /Microsoft-Server-ActiveSync
- Exchange Web Services /ews
- Offline Address Book /oab
- AutoDiscover /Autodiscover
Creating a health check is Route 53 for one of those services is simple. Give the health check a meaningful name and fill out the details so that a HTTPS check is performed against your Exchange namespace, and the appropriate virtual directory with /healthcheck.htm appended to it.
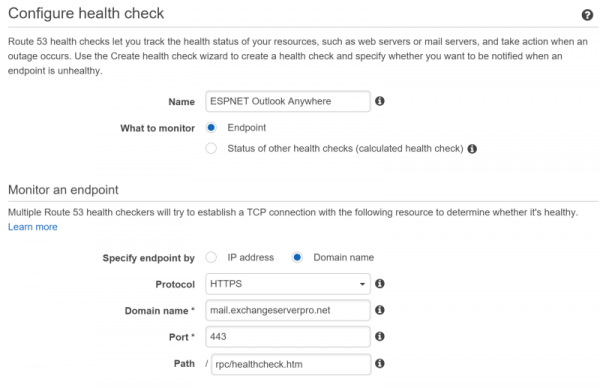
Double check the Advanced settings to ensure SNI support is enabled, if your load balancer requires it.

The next part of the wizard prompts you to set up alarms. You can choose not to set up alarms at this time if you’d prefer to just set up the health checks and test them out before you potentially blast yourself with alert emails.
But if you do want to set up an alarm, either create a new Simple Notification Service (SNS) topic, or if you’ve already created an SNS topic while setting up a previous alarm you can choose the existing one.
Note that at the time I’m writing this the user interface seems to have the Existing/New toggle the wrong way around, so watch out for that if you’re doing this step yourself.
Note also that SNS topic names can’t have spaces. The interface isn’t very helpful with this, it will allow you to try setting an SNS topic name with spaces, then fail to create it and throw an error. That’s okay though, you can add an alarm to an existing health check later if you need to.

The email address you enter for an SNS topic needs to be confirmed before it will receive any alarms, so watch for a confirmation email in your inbox after you set it up. Common sense also says you should use an alert email address that is external to the Exchange organization that you’re monitoring. Obviously if your Exchange server goes down, you’re not going to be able to receive an alert email. So you should use Gmail.com or Outlook.com, or consider also adding SMS (text message) notifications to your SNS topic so that the alerts are sent to your mobile phone.
Repeat the alarm setup steps until each of the Exchange services is being monitored. Now you’ve got each of the 8 Exchange HTTPS services being monitored individually, and if you chose to configure alarms then you’ll receive alarms when any of the services are unavailable.
Let’s take it a step further. Consider that some services might be less critical than others. Perhaps you’re not concerned so much about OAB being unavailable for moderate periods of time, or you don’t think OWA should be monitored because nobody in your organization uses it. You can tune the alarms for each service independently, either by turning the alarm off entirely, or by adjusting the conditions used for the alert. For example, you might set an alarm threshold for 1 day for a less critical service, and 1 minute for a critical service.
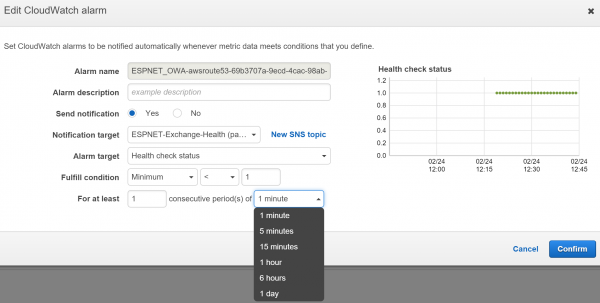
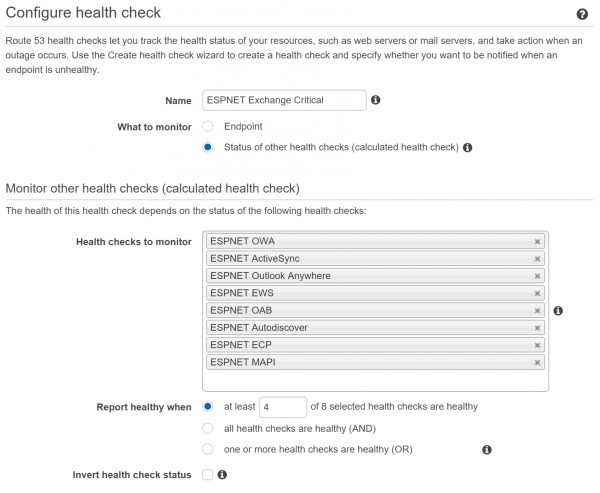
You can also consider creating alarms based on the status of other health checks, or what are called “calculated health checks”. An example of this is having your per-protocol alarms go to one email address, but then have a calculated health check that throw an alarm when more than X number of health checks have an alarm. This extra alarm can be filtered differently in people’s inboxes so it is less likely to be missed, or could be sent to different recipients such as a higher tier of support or a critical incident manager.
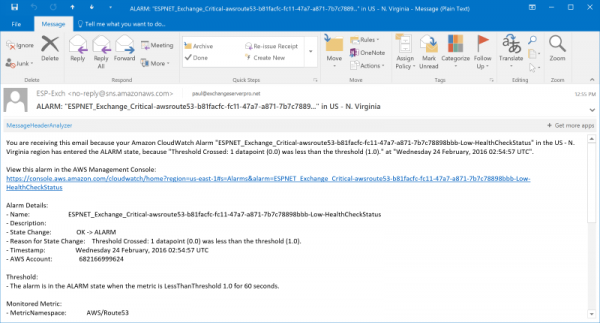
The email alerts themselves are not very user friendly when you let AWS create them for you. The average user might find them too confusing, but they are perfectly find for a technical audience. If you need to customize the name to something friendlier you can so by manually creating the alarms instead.
If latency is important to you, then you can also add latency monitoring to your health checks and configure alarms that will fire when there is high latency on a service.
As you can see the health check features of AWS Route 53 are quite useful, and the costs are trivial. This makes it an interesting alternative to other paid monitoring solutions such as Pingdom (which I use to monitor this very website). Monitoring the status of HTTPS service works well. Monitoring other TCP services such as SMTP, POP and IMAP can also be performed, but not to the same degree as other systems that perform a full application test of those services.
If you’ve already got an AWS account and you’re using other AWS services already, adding in Route 53 health checks will be simple. At the very least, if you’ve got no external monitoring of your Exchange services today, or you’re evaluating multiple tools, then you should take a look at Route 53.
[adrotate banner=”48″]



What about if we cant have Load Balancer ??
What about it? You can still monitor Exchange server health whether you’ve got a load balancer or not.
Hi Paul,
Great idea. Not sure how you are getting around authentication though? Each of those sites requires authentication yes? Or am I missing something
The healthcheck.htm doesn’t require authentication.
This is awesome!! Thank you for posting this how to