Databases that are being replicated within an Exchange Server 2013 database availability group can generally be considered to be either active or passive at any given time.
There are also other states that the database may be in, such as seeding, or due to health problems, but for the purposes of this article we’re going to be looking only at healthy database copies.
The active database copy is the one that is mounted on a DAG member and is being used to serve clients. The passive database copies (up to 15 of them) are those that reside on other mailbox servers within the DAG. Changes are replicated from the active database copy to the passive database copies.
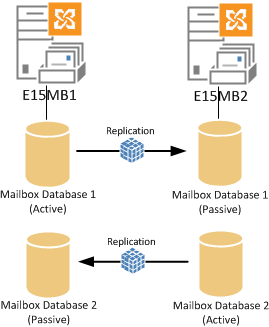
The active database copy can be “moved” between DAG members that host a copy of that database. Although some people consider this to be an actual “move” of the data from one server to the other, in actual fact what is occurring is the active database copy is dismounted, and one of the passive database copies is then mounted.
There are two ways that the active database copy can be moved to another DAG member:
- Failover – this is an unplanned event, such as a failure of the server hosting the active copy
- Switchover – this is a deliberate, administrator-driven event, such as during server maintenance
In this article we’ll look specifically at the database switchover.
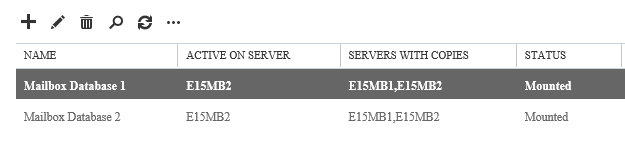
Consider a two-member DAG with two databases. Each server hosts one active and one passive database copy.
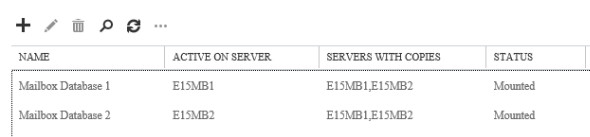
To move Mailbox Database 1 to E15MB2 we can simply highlight it and then review the status of the database copies. Note that in this case the passive copy on E15MB2 is healthy, with no copy queue length issues and a healthy content index state as well.
Under those conditions we can proceed with the switchover by clicking the link to Activate the database copy.
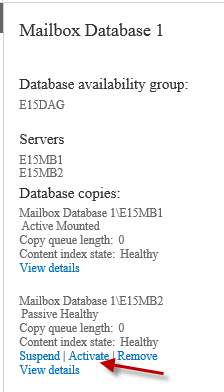
You’ll be prompted to confirm the action, and then a progress bar let’s you know when the operation is complete.
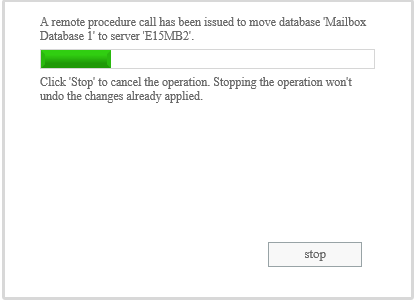
Click Close when it is finished. In this case we can see that the database is now active on server E15MB2.



Hi Paul
I have to move my active db to another server as an active db (exp: exc13srv1 to exc13srv2), i used GUI ecp to move the db,as information i got that the db has been moved successfully to exc13srv2, i refreshed the page and the db is still on exc13srv1, when i checked in exchange shell that has been moved to exc13srv2,but not in ecp,i am waiting maybe there was some delay,but it still the same. Do you have any suggest that i can do ?
Regard
Bagus INA
Hi Paul, much interesting, Thanks for all your Expert advise .
Please provide a link for 3 Node DAG configuration, our current setup is as below
1. 2x CAS and 2x Mailbox in Main site and FSW configured on one of CAS server .
2. Planning to build 1 x CAS and 1X Mailbox at DR site and configure
3. Is there any configuration required for 1xCAS on DR site
4. Please Note : we don’t have a any third Site for Witness server (FSW) and hence have to manage between these two sites. We will use LB to route the traffic if it is declared the main site has network issues or down
Regards
IAN
I have 2 exchange 2013 , one is master and other slave, front end and backed both are same server.Database have 3 configured.if master goes down then mail will work from slave is it possible ?how
Great Stuff, Thanks for all the helpful info
thank you very much
Hi Paul,
Although we have a exchange 2013 DAG set up, but our maintenance cycles haven’t been as seamless to the end users as I’d like them to be. (Following your article above caused our outlook web access page yo list itself as unavailable for example.)
Please take a look at my procedure below and let me know if I could be missing something in deed or configuration, thanks!
We have two exchange servers, each virtual server has a copy of both exchange databases on it.
Usually after checking the Failover Cluster Manager to make sure everything is green (databases, nodes, witness, and connections) I run a series of exchange commands to put one of the nodes into maintenance mode and verify its status:
Set-ServerComponentState n2 -Component HubTransport -State Draining -Requester Maintenance
Restart-Service MSExchangeTransport
Set-ServerComponentState n2 -Component UMCallRouter -State Draining -Requester Maintenance
Redirect-Message -Server n2 -Target n1.cn.local
Suspend-ClusterNode n2
Set-MailboxServer n2 -DatabaseCopyActivationDisabledAndMoveNow $True
Set-MailboxServer n2 -DatabaseCopyAutoActivationPolicy Blocked
Set-ServerComponentState n2 -Component ServerWideOffline -State Inactive -Requester Maintenance
To verify that a server is ready for maintenance, I perform the following tasks:
To verify the server has been placed into maintenance mode: (all but 2 should be Inactive)
Get-ServerComponentStaten2 | ft Component,State -Autosize
To verify the server is not hosting any active database copies: (policy blocked)
Get-MailboxServer n2 | ft DatabaseCopy* -Autosize
To verify that the node is paused: (state paused)
Get-ClusterNode n2 | fl
To verify that all transport queues have been drained: (mesage counts = 0)
Get-Queue
I download and apply updates with reboot(s) as needed to the downed node.
I run a series of commands to bring the node back up and transfer the workload back to it.
To designate that the server is out of maintenance mode, run Set-ServerComponentState n2 -Component ServerWideOffline -State Active -Requester Maintenance
To allow the server to accept Unified Messaging calls, run Set-ServerComponentState n2 -Component UMCallRouter -State Active -Requester Maintenance
To resume the node in the cluster and enable full cluster functionality for the server, run Resume-ClusterNode n2
To allow databases to become active on the server, run Set-MailboxServer n2 -DatabaseCopyActivationDisabledAndMoveNow $False
To remove the automatic activation blocks, run Set-MailboxServer n2 -DatabaseCopyAutoActivationPolicy Unrestricted
To enable the transport queues and allow the server to accept and process messages, Set-ServerComponentState n2 -Component HubTransport -State Active -Requester Maintenance
To resume transport activity, run Restart-Service MSExchangeTransport
To verify that a server is ready for production use, perform the following tasks:
To verify the server is not maintenance mode, run (all active) Get-ServerComponentState n2 | ft Component,State -Autosize
If you are installing an Exchange update, and the update process fails, it can leave some server components in an inactive state, which will be displayed in the output of the above Get-ServerComponentState cmdlet. To resolve this, run the following commands:
Set-ServerComponentState n2 -Component ServerWideOffline -State Active -Requester Functional
Set-ServerComponentState n2 -Component Monitoring -State Active -Requester Functional
Set-ServerComponentState n2 -Component RecoveryActionsEnabled -State Active -Requester Functional
I repeat the above process for the other node in the cluster with the names reversed.
I have a tutorial on maintenance prep here:
https://www.practical365.com/exchange-server/exchange-2013-installing-cumulative-updates/
You’ve got some extra steps but that’s normal. It’s something you can build on by taking into account any specific variables on your own environment.
If OWA is breaking when you do switchovers or maintenance then you should look at whether you’ve properly configured your client access namespaces and high availability (either load balancing or DNS RR).
Hi Paul,
Was wondering if you could provide feedback on this possible DR scenario.
1. Main site loses both internet and private tunnel to the DR site. 3 Member DAG (DAC enabled CAS/MBX 2013 roles on each) spread across sites (2 members in main site and 1 in DR which is in passive mode). Been called to flip mail routing to DR site
which is not affected by the outage.
2. Users are working in main site sending email to external and internal clients not realizing there are issues. I as an IT Admin am not available in the main site so cannot run the DAG commands to stop the main site exchange servers
which are running fine. I do the DNS record flip and activate the databases in DR (Stop-Clussvc and Restore-DatabaseAvailabilityGroup DAG1 -ActiveDirectorySite DR.)
3. My question is what would happen if services are restored at the main site and the databases are still mounted there since the servers were fine all along? What would happen to emails that were flowing between users at the main site?
Would there be data loss or database corruption between the main site and DR? How would someone deal with this situation?
Thanks
1. You’ve lost me at “3 member DAG”. I suggest you go read the Preferred Architecture from Microsoft and strongly consider following it.
2. If users can connect to the primary servers, but can’t connect to the DR servers (I assume that because the servers have lost comms due to the link failure?), why would you failover to the DR site?
3. Database copies can only be active in one place at a time. If you have them active in two places, they diverge. If you allow the primary site to continue active for a period of time, do a datacenter switchover to DR, and then later restore service, you’ll likely lose data. You need to decide if that risk is more or less impactful than the availability of the service.
Best is to use move-activamailboxdatabase -server .. In case of large number of servers and ECP causing slownesss always advisable to move via EMS
We have 5 databases in DAG. So, instead of clicking activate on each one, can i do server switchover and get same result? We need to restart server that currently holds active db. If i go to eac/servers , select server that is passive and click server switchover, i get te same thing as manually clicking Acivate on 5 dbs? Or is the somethin more that is happening with server switchover?
Thank you in advance
Hi Paul,
this is Hossein who has conversation before with you about shared mailbox group base access, so i have an issue regarding DAG in Exchange 2013, as i want to use first DAG’s node as active node and i moved the DBs to that server but after a few hours the databases move to second node as active node, would you please let me know how i can fix this issue permanently, please take note i have another DAG on this environment and i don’t have this issue on second DAG.
as i compared both of them to find root cause but i couldn’t find any difference.
i appreciate if you answer this conversation.
Hi Paul,
Is it possible to configure “retries” or wait time to failover?
In the precise case, we have a DAG across 2 sites and when our firewall reboot, Exchange 2013 is doing his job at the perfection… meaning that the database located at our secondary site failover to our primary site and database is available again.
Considering that the connection is dropping for 30sec to 1 min, is it possible to prevent Exchange to failover and wait a bit before doing so?
Thanks.
No. The DAG is behaving as it should behave.
Thanks Paul.
So in my case I will first shift db from EXCH01-Mounted to EXCH02-Healthy. Hope you will not mind as I am doing this activity for the first time, that is why bit confuse due to DAG.
Mr. Paul, thanks for your swift reply. I just want to know before update I have to shift my DAG in maintenance mode and move my mounted db on healthy server? or .StartDagServerMaintenance.ps1 script will perform this task it self?
No, that script is for Exchange 2010 only. You need to use the steps shown in the article I linked you to.
I need help to run CU12 on my exchange server2013. I have DAG with two servers EXCH01 & EXCH02. Server Status is EXCH01-Mounted & EXCH02-Healthy. I need to complete this task. Please help. what should I do first. I have download the update and already run ADScheme and AD prep.
Here you go:
https://www.practical365.com/exchange-2013-installing-cumulative-updates/
Thanks Paul. I will take a look into it and get back to you.
Hi Paul,
I am finding your forum very beneficial as I am new to exchange hoping you can shed some light. In exchange 2013 I have a DAG with 2 servers one in PROD and the other in DR and one database. The PROD has the active and the DR has passive copy. When I test replication via exchange shell it fails on DatabaseAvailability Error : there were database availability check failure for database that may be lowering its availability, Availability count:1 Expected Availbility Count 2, we have database auto activation Blocked by design. Application Event ID 4374 MSEXChange Repl is generated with above error as well. When I check EAC the DR database is healthy and PROD is mounted fine. I am starting to think this error is generated due to auto activation or? Also I have dismounted the database but it was clean.
Thank you
Yes, it’s because you’ve blocked activation on your only other copy.
I’m guessing you want to avoid running the active database on the DR side. A better approach is to set this other option instead:
https://www.practical365.com/databasecopyactivationdisabledandmovenow/
That will allow failovers to occur automatically, and then as long as the Prod side is healthy Exchange will move the active copy back to the Prod side automatically.
Hi Paul,
Great work, thank you for this. I have a question in order to clarify something that happens in my network. After a restart of 1st exchange server (the server “frozen” and I had the only solution to restart it) the data bases switched on 2nd server. In this moment I have DB1/DB2 on exch1 and Db1/DB2 on exch2, but they are active on server 2 instead exch1. It is important that the Db s be active on a specific server, for example on exch1, or it is the same thing if they are on exch 1 or exch 2? The configuration now is this:
DB1->active on Exch2->Server with copies: Exch1, Exch2->Mounted->Bad copy 0
DB2->active on Exch2->Server with copies: Exch1, Exch2->Mounted->Bad copy 0
Hi- Thank you for posting this series on the DAG. I’ve learned a lot. Of course, I have a question. First, I’m upgrading/migrating from Exchange 2010. I built three Exchange 2013 servers with both CAS and Mailbox roles. I created my DAG and have passive copies of my DB on the other two servers. So… How do I handle internal DNS records pertaining to the three servers? Do I put the IP I assigned to the DAG? Or three A records and MX records for each of the three servers? I’m just wondering how clients find Server 2, for example, when server 1 goes down…
The DAG IP is not a client access endpoint, so none of the client access namespaces should ever resolve in DNS to that IP.
Some reading on CAS HA:
https://www.practical365.com/exchange-2013-client-access-server-high-availability/
Basically, you’ll configure your CAS namespaces, and then either use DNS round robin, or a load balancer, to distribute the traffic to the available CAS.
MX record are not used for client connectivity.
Hi Paul,
I deployed a 2013 DAG following your instructions. It’s up and running. However, I want to test it by rebooting one of the node. I’m worry that the received connector only have the IP of my previous mail server (now a member of the DAG). Should I change that to the DAG cluster IP? or should I just add the IP of the second mailbox server that belongs to the DAG?
Never mind. They entry for the second mailbox server is there.
Hello Paul,
A quick one not sure if it possible or not.
I have DAG with 2 exchange severs, and I have suddenly had disk corrupted so lost the active copy of the mail database and log files. Now for some reason the failover didn’t happen and all I left is with passive copy of database and respective logs. Is it possible to make this passive copy an active copy and mount this database?
Thanks
Sure. Have you tried to activate it?
Yes I have and its wants to copy the log files from the active server, throws the error but as I said we have lost the active completely. What are options left.
Have you researched that error? You haven’t provided the exact error so I can’t offer any suggestions other than look at the additional switches for Move-ActiveMailboxDatabase which can override the missing log thresholds.
https://technet.microsoft.com/en-us/library/dd298068%28v=exchg.160%29.aspx?f=255&MSPPError=-2147217396
But make sure you understand the implications and have a backup of the EDB.
We currently have two Exchange 2013 servers and a witness server at our main office. For HA/DR purposes we’d like to add a third Exchange 2013 server to the DAG in a branch office (we have several sites which are all connected to one and other via private fast links). Our plan is to leave Exchange server1 & 2 at our main office, move the witness server to a branch office and setup Exchange server3 at our DR office and add it as a DAG member. We would then enable DAC and in the event of a failure at our head office we would perform a datacentre switchover to our DR site.
Does this sound correct or have I miss-understood the concept?
I’d recommend you should put two DAG members in the second site.
Other than that, draw a picture of your proposed topology, including networks links. Look at each failure point (server, datacenter, WAN link, etc) and work out whether the DAG will retain quorum or not in the event of that failure. You’ll be able to identity which failure scenarios will keep the DAG online, and which will require manual intervention.
Great article! I would recommend that you add a snippet about enabling DAC mode and what it does though. I had an issue recently where our primary data center (one mailbox server and witness) went down, and I had an extremely difficult time activating the DAG at our secondary data center (one mailbox server only) without DAC mode enabled. DAC mode makes switching to a secondary site during an outage much much simpler and also helps to prevent database divergence when recovering your primary site should a connection between the two not yet be available.
On a side note, do most people still run an antivirus agent on their Exchange servers? I’m following the MS recommendations for exclusions, but you never know if that agent is behaving accordingly. We have desktop AV and a hosted spam/virus filtering solution for incoming/outgoing email so just wondering if it’s even worth it to have AV on the Exchange server.
Paul,
We have two DAG members, each with 4 CPUs and 40GB RAM. For over a month, we were running in co-existence with Exchange 2007, having all of our mailboxes distributed between four databases on 2013 while the public folders remained on 2007. Last weekend we completed the public folder migration and there have been challenges ever since. The four databases with the user mailboxes are active on one server with passives on the other while we have one database with all the public folders active on the other with passive copy on the server with the active user mailboxes. This “public folder mailbox” database is 145GB and our public folders consists of around 75k folders and 13 million emails. We seem to get the occasional event 164 for this public folder database which causes it to activate on the other server with all the active user mailbox databases. This hoses up all of our Outlook clients (cached mode but public folders are online mode). A few minutes later the event 164 will appear on that server and the public folder database switches back. A few minutes later everything is fine again. This causes almost 10 minutes of downtime for our users because Outlook is not responding. The storage is on an iSCSI SAN with dedicated RAID 5 disks for each email server. However the active and passive copies on one server all reside on one RAID 5 drive (3 spindles) and the active passive copies of the other server are on another set of RAID 5 disks (3 spindles). The tlogs of both servers are sharing a RAID 1 (2 spindles). I/Os, CPU, and memory don’t appear to be excessively high when event 164 appears. Any suggestions that we should try?
Log Name: Application
Source: ExchangeStoreDB
Date: 5/26/2015 5:38:50 PM
Event ID: 164
Task Category: Database recovery
Level: Error
Keywords: Classic
User: N/A
Computer: xxxxx
Description:
At ‘5/26/2015 5:38:43 PM’ the Exchange store database ‘DB_PF’ copy on this server timed out on periodic status check. For more details about the failure, consult the Event log on the server for other storage and “ExchangeStoreDb” events. A successful failover restored service.
Paul,
I cannot find any documentation that states the network requirements for the third site witness. What is the tolerated latency on the connection between sites with DAG members and the witness in Azure or on-premise third site? Do you know if that is published anywhere?
Thanks,
Adam
Thank you Paul! Learned a lot from your posts.
I have a Disaster Recovery situation and would like your advice. I understand that only one database can be active at any one time.
However, are there workarounds to activate both databases at DR site and Production site for a period of time?
Reason: When we conduct DR tests, we would only like a subset of users to access mail boxes in the DR site via the Internet link from our offices. The rest of users should access their mail boxes from their our office internal production connectivity so they will not be affected by Internet links latencies, etc.
In normal circumstances, a DR test should simulate a real disaster where all users will access DR site mail boxes via the Internet Link be it slow or performance degradation because a real disaster has indeed happened.
But, we wouldn’t want to alarm the users so we were thinking of only having a subset of users to test the DR mail boxes while rest works business as usual. We didn’t want all 1000 over users to access email over the Internet during a DR test.
The switchover/failover is per-database, so you can choose to only switchover or failover specific databases.
However, for any given database, only one copy of that database can be active at any given time. If you have two copies of the same database active at the same time you have effectively created a split brain condition which is a very bad thing.
In your situation I would simply advise users that a DR test is being undertaken and that some minor performance degradation may occur as a result. In reality any cached-mode Outlook user should remain blissfully unaware of any latency issues that may occur.
Hi Paul,
When doing the switchover, how much downtime is there?
It depends on how smoothly the switchover goes, but a few seconds would be considered normal. End users shouldn’t notice anything, especially if they’re running Outlook in cached mode.
Hello Paul,
i just found this great Article Series. However there is one question that makes me puzzeled.
Is there any benefit of a DAG Deployment if Exchange is already hosted on a Hyper-V failover Cluster with Shared Storage ? The only benefit i can see is to have a somehow “desaster” copy available on any external storage.
A single VM is not a highly available solution. Virtualization can protect you from some failure scenarios, but not from many others. Even something as simple as performing routine patching of the server is impossible to do without downtime if you’ve only deployed a single server.
In my current environment even though we have storage failover we also have a DAG, I ran to an scenario, where one of the exchange server, didn’t reboot after a patch update. But we didn’t have any downtime because the as soon the witness server found that server was down, migrated the copy to the second Server.
“as soon the witness server found that server was down, migrated the copy to the second Server”
That isn’t really how it works, but I’m glad your DAG is doing its job.
Pingback: 4 weeks to MCSE : Messaging – 70-341 (4/5) | David Bérubé's blog
Hello
I have one question and need advice.
I would like to make a site where I would have two CAS and two DAG-s, every CAS would connect to different DAG. Those should be two different sites connect with a link that could fail. If the link fails users on both sites should be able to access their emails and normally receive and send emails. But as I understand it that would mean that at one point there would be two databases that would both be active? What would happen once when the connectivity between the sites would be restored, how would the differences be replicated?
Are manual failovers possible, if there is a network outage between the two sites where MB’s reside?
If there’s a network outage between two sites the DAG should manage that itself by failing over databases to the site where quorum is able to be achieved.
I’ve been speaking with a few Exchange consultants and they’ve been informing me that AUTO failover is not possible between two sites. Mainly because of client access and DNS records that would need to be changed. Seems like there would be a lot of user intervention to be able to failover to a DR site. Do you agree?
Depends which version of Exchange and how they’ve deployed it. For Exchange 2013 (which this article is about) it is entirely possible to have automatic database failovers to other sites without manual intervention required.
Most informative post yet for this particular situation. Thank you.
Hi Paul,
I have a mailbox database that has a copy at another site. Replication takes pretty long and there is almost always a copy queue. What happens if I activate the copy which still has a copy queue length of non-zero value? Furthermore, what will happen if I activate the original database? Will the changes made to the copy (which still has copy queue) be reflected to the original database?
It should attempt to copy the remaining logs before it mounts. When that copy is active the previously active database will become a passive database copy and be updated via continuous replication.
Hello Paul,
So does that mean I have to wait until the copy queue is 0 before the passive database becomes active?
Basically yes.
I have a 2010 Exchange server which currently contains my mailboxes and in a DAG I have 2 2013 servers. All 3 servers currently live in the same data center A. Once I move all the mailboxes over to 2013 I plan on sending one of the 2013 servers to a remote data center B. Are there special preparations I should take to do that? I expect to overnight the server so it would be up in at least 48 or worst case 72 hours.
It will have about 300 mailboxes, 800 Gig among 5 dbs. My witness server is already in a different data center C.
?
As always, very helpful & well done. I have also read your related article “How to Install Updates on Exchange Server 2010 Database Availability Groups” and am wondering if there are any important changes for Exchange 2013.
Yes, it is a completely different process.
https://www.practical365.com/exchange-2013-installing-cumulative-updates/
Great article!
Is the procedure to fail over to a datacenter basically the same as in 2010 where you need to stop nodes and activate the alternate FSW?
Thank you
Brian
Great info! Just started a migration from Domino to Exchange and I noticed that over the weekend the mailbox databases failed over to another server. Is there a log somewhere that will tell me whenwhy this happened? Thanks
Yep, all these events are written to the event logs on the servers.
Hi would need some advices here.
We had our databases replicated through a wireless connection to the DR databases.
But when the connection drop (time out) the databases are mounted there automatically which is not what we want exactly ,so we have temporarily disable automatic fail over and will switch over manually if need arise.
What we want exactly is that the databases don’t mount WHEN there is a connection problem to the DR.
Is disabling Automatic Database Mounting permanently a solution ??
Thanks to advise
I have a question on exchange 2013 dag failover,
1. I understand that in exchange 2013 I can give same URL name for eg.mail.contoso.com in both datacenter for all services, and because of this I can assign two IP address to mail.contoso.com that is IP at primary datacenter and IP at secondary datacenter. But how can I make sure that my oulook or any other clients continuously connected to primary datacenter IP? if I give both IP in DNS how oulook will choose primary datacenter IP as primary connection pont? I hope it will randomly select and may not be suitable for my situation.
2. Exchange 2010 datacenter switchover process is mentioned in the TechNet article,
http://technet.microsoft.com/en-us/library/dd351049(v=exchg.141).aspx
how can I manually activate datacenter in case of exchange 2013? I don’t have a third location for witness server for automatic failover. I hope it will be same as exchange 2010.
You would need to do geo-DNS or geo-loadbalancing, otherwise yes the clients will randonly pick one CAS IP and connect to it regardless of where the active database copy is.
However, that isn’t necessarily a bad thing if the WAN between datacenters is fast enough. And it should be reasonably fast if you’re stretching a DAG across it.
Thanks Paul,
I have some other issue encountered, i am experiencing an intermittent send/receive emails for all migrated users.
Workaround:
1. Restart this services Microsoft Exchange Information Store.
2. On OWA – i just restart my IIS services.
Please share on thoughts
Godspeed!
Hi Paul,
Greetings!
This is very helpful. i just have some question in mind. I have my Exchange 2013 DAG in place.
When is the best time to replicate my mailbox database to other dag member?
I’m planning to replicate after office hours. And also, what is the impact when i replicate to other mailbox server?
Does my exchange users may encounter downtime or a delay of the sendreceive email?
Please share your thoughts on this.
When you add a database copy on another DAG member the replication begins and runs continuously from that point onwards, unless it is suspended for reasons of maintenance or due to a fault.
Replication does not cause any downtime for the end user or delays on email, unless the server is overloaded which is more of a general problem than anything.
Hi Paul,
First I want to thank you for all your posts, it help us to get better in our jobs. Quick question can I add a secondary FSW to the DAG?, and how I can accomplish that?. I want to set two FSW’s one physical and one Virtual.
Thanks,
You can set an Alternate Witness Server. However that does not mean you have two file share witnesses. The AWS is only relevant in datacentre switchover scenarios (ie disasters).
Explained here:
http://blogs.technet.com/b/exchange/archive/2011/05/31/exchange-2010-high-availability-misconceptions-addressed.aspx
Paul
I have two mailbox servers and eight databases that I try to spread between them, but after applying the latest rollup for Exchange 2013 I notice that the databases all seem to migrate to one server or the other. Is this normal?
Databases may failover for various reasons. You should look at your server event logs if you think that unplanned failovers are occurring.
You can somewhat control which database copy should be the active one using the Activation Preference setting shown in this article:
https://www.practical365.com/exchange-2013-dag-database-copies/
You can also rebalance your DAG after maintenance by running this script (same process for Exchange 2013 as for Exchange 2010):
https://www.practical365.com/how-to-rebalance-mailbox-databases-in-a-dag-with-exchange-server-2010-sp1/
Thanks for the shell commands. Upon further review it appears the DB failovers are connected to a Veeam backup I am running against the mailbox servers.
Hi, Cartos
I have Exchange 2013 CU3 installed and I have the same problems with you. I have two servers and four databases, after moving one or two databases to another server, it will move back automatically, but all the databases can activate on any single server. Have you found a good solution without using the script?
Thank you.
Nile
I am having some issues understanding from my event logs whether my DAG failure was a failover or a switchover. Is there a way to identify easily if a switchover and which user initiated? My first event is 260 Initiating store RPC to dismount database.
Hi Paul
Thanks for the swift response! My hardware is way over spec, we utilised a dell poweredge as it was just lying around doing nothing that is comprised of 4 server systems for the exchange environment, 2 combined cas and mbx servers both with 64 gb of ram, 2 6 core cpus each, 140 gb raided volume each for the os and one 2tb raided volume each for the mailbox databases and logs. Given the above do you think it would be worthwhile me creating the extra mb db as stated in my previous comment?
Thanks
Well Exchange 2013 can support quite large databases. If you’re satisfied that performance is not going to be an issue then there are other reasons to consider multiple databases, such as backup/restore times.
Hi Paul
Awesome articles, they are real help for people like me getting to grips with Exchange 2013 for the first time.
I just have one question regarding mailbox databases. I read above that it is not necessarily best practice to have more than one mailbox database, but are there advantages to say have two mailbox databases replicated on a DAG, say you have two combined CAS and MBX servers (my set up). Is there a performance gain or redundancy gain of having ‘mailbox database 1’ active and mounted on server A with a passive copy on server B and another ‘mailbox database 2’ mount and active on server B with a passive copy on server A. Lets say both DB’s have all your user and other mailboxes spread across both databases.
Any advice or opinions greatly appreciated
Thanks
Exchange 2013 has some store improvements that mean lower IOPS for passive database copies, so in theory yes there is less load on each server if you distribute your active DBs 50/50 like that.
However you should always size your hardware to suit maximum performance requirements, ie when both DBs are active on one node, which will occur regularly due to maintenance, failures, automatic failovers, etc.
Hi Paul,
I have built a DAG group but only have the one mailbox database. Is it best practice to have 2 databases?
No you can have as few or as many databases as you like (or as suits your needs)
Great Stuff, Thanks for all the helpful info
Pingback: Exchange Server 2013 Database Availability Groups