SharePoint site and information architecture has been around long enough to be an established practice and area of expertise in the SharePoint world. What’s new about it, however, is its elevated role in Microsoft 365 compliance. Architectural decisions made in a tenant can have lasting, follow-on effects which information architects need to be aware of. This post highlights some key points about how these decisions can affect managing compliance at scale by providing structure (sites, content types, and metadata) and governance (compliance controls) to SharePoint.
Although Microsoft has modernized many of the tools and techniques for site and information architecture over the years, a heightened awareness around non-compliance has made this the right time to examine site and information architecture through a compliance lens.
Disclaimer:
This post covers SharePoint documents only; however, in the modern workplace, compliance needs to manage all types of records and so extends well beyond SharePoint Online to other workloads as well (Exchange Online, OneDrive for Business, Team chats and channel conversations, Yammer, etc.)
Tip: Build a new/renewed partnership between information architects and information management teams within an organization to implement compliance at scale across Microsoft 365.
To demonstrate how SharePoint site and information architecture components have evolved over the years, let’s look at some modern ways they can be leveraged for compliance and other “up-and-comers” you should get acquainted with to expand your options in new and interesting ways.
Developing the SharePoint Information Architecture
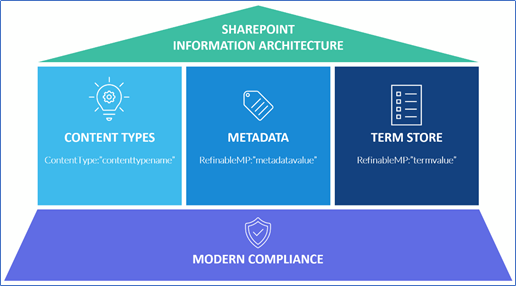
Figure 1 shows the essential components of a SharePoint information architecture. Let’s start with content types, which are still an information architect’s go-to assembly for organizing both structured and unstructured content across SharePoint sites (examples are contracts, invoices, and purchase orders). Content types can enhance search, provide organization options within a list/library, enable workflows, and apply templates.
How can they be used for compliance? By organizing content into content types, it creates the opportunity to auto-apply retention labels to content by targeting a content type. To do this, you create an auto-label policy and create a condition to match a specific type of content:
Due to the scale of information now stored in SharePoint Online, manual application of content types and compliance controls is no longer feasible nor sufficient. Leveraging automation like auto-label policies should be top-of-mind for organizations looking to implement compliance at scale. It’s important to understand that accounts need E5 licenses for any compliance feature which involves automatic processing, including auto-labeling. Unless you’re in the fortunate position of already having E5 licenses, the additional licensing cost can be a significant factor to consider in your compliance strategy.
**One of the Up-and-Comers I referenced at the start of this post uses AI models to automate the application of content types (SharePoint Syntex). This addresses the challenge many organizations have today of relying on end-users to manually set or default the content type. There is an additional license cost with SharePoint Syntex – more detail is in the Up-and-Comers section at the end of this post.
Metadata
Metadata has long been a controversial topic due to the “burden” it places on an end-user to apply metadata for documents and is often perceived as an unreasonable ask in the modern workplace. Document collaboration using Teams and replacing traditional email attachments with “cloudy attachments” are two modern capabilities that highlight the diverging needs of classic metadata design and modern collaboration in organizations today. In the past, where users might have thought about document metadata when creating new files, today they probably won’t when they create documents through Teams. The upshot is that many documents end up stored in SharePoint with minimum metadata. This isn’t bad because the documents are safer in SharePoint than they are on local drives which makes them discoverable, but the mass of documents created through Teams is far less organized than might have been the case in the past.
Due to this shift in how documents are handled by end-users in the modern workplace, the need for automation rather than relying on an end-user to apply metadata is increasing in importance particularly when it comes to compliance. Compliance controls, like retention policies, can be broadly published to locations providing the information governance your organization requires without the need for metadata. This limits the requirement for metadata to your targeted records management needs (E.g., Contracts, Invoices, Financial Statements, etc.) where compliance controls are unique and therefore require the ability to identify specific content. This can be done by using metadata as well as some of the new capabilities in the Up-and-Comers section like SharePoint Syntex and Trainable Classifiers.
With these metadata limitations in mind, there is still value and purpose for metadata for specific use-cases. 2 examples where I’ve seen metadata used successfully:
- in structured content scenarios where there are well-defined processes and owners around managing the content (Contract management, for example). Some compliance controls, like retention labels, can be automatically applied based on metadata values if you have an E5 license.
- within document sets where metadata is applied once at the document set level and configured to automatically push the metadata values to all documents contained in the document set, without requiring an end-user to apply it. This will enable some compliance features described below. It’s important to know that document sets work well in SharePoint however some capabilities are not available in Microsoft Teams. For this reason, this option will only be beneficial when used directly from SharePoint.
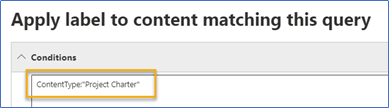
How can they be used for compliance? If documents have metadata applied, an auto-label policy can find and apply a retention label to any document with matching metadata, as shown in Figure 3:

**Like content types, one of the Up-and-Comers I referenced at the start of this post, SharePoint Syntex, uses AI models to automatically extract metadata out of structured documents (Forms Processing model) and unstructured documents (Document understanding model) and automatically add them to a library. This addresses the challenge many organizations have of relying on the end-user to manually tag metadata. There is an additional license cost for this feature – more detail is in the Up-and-Comers section at the end of this post under the SharePoint Syntex section.
Term Store
The Term store has long been a key component in an information architect’s toolkit. Although it is also metadata and could rightfully be included in the last section, a key differentiator of the term store over other types of metadata is the hierarchical structure it provides and the tenant-wide management of it with assigned ownership. It allows information to be grouped, classified, and labeled consistently across a SharePoint tenant. Like a content type and other types of metadata, items tagged with a term from the term store can be used to enhance search, provide organization within a list/library, and enable workflows. The tenant-level term store is considered part of modern content services within the SharePoint Admin Center demonstrating its importance and elevated level of importance over other types of metadata.
How can they be used for compliance? By leveraging your tenant-level term store via managed metadata columns applied to libraries in sites, you can automate compliance. You can automatically apply a retention label to an item by using the retention label auto-apply capability that targets a specific term value. The benefit of having the terms defined at the tenant level is any SharePoint site within the tenant can reference them!

**SharePoint Syntex covered in the Up-and-Comers section below can also extract term values out of a document and assign them to a managed metadata column. There is an additional license cost for this feature.
Site Architecture
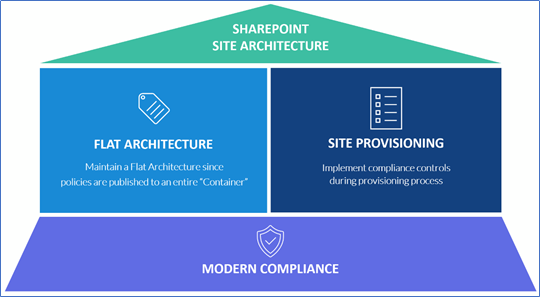
Flat Architecture
Keeping a flat SharePoint site architecture is no longer a new concept and the out-of-box provisioning model used for Microsoft 365 Groups (and picked up by Teams and SharePoint team sites) supports the flat structure. The classic, hierarchical, nested model of site/subsite architecture has been pre-empted with modern and flat. Organizations that have chosen to stay with this flat model (rather than provisioning subsites) will benefit when it comes to applying several compliance controls as well!
How can a flat architecture help compliance? The following compliance controls can be published to a location. A location is an Exchange Mailbox, Microsoft 365 Group, OneDrive account, or SharePoint site. (There are no conditions to publish a label to just a subsite since it’s not a location):
- Retention Policies
- Retention Label Policies
- Auto-Label Sensitivity Label Policies
- Data Loss Prevention Policies
**You cannot publish a sensitivity label to a document library in a site.
Site Provisioning
The ability to automate the SharePoint site request/provisioning process is not a new concept. Many organizations have done exactly this to inject some rigor and control around it. It has traditionally been a great point to introduce some level of governance into the SharePoint environment in an automated and consistent way. The degree to which organizations do this is largely dependent on how much control an organization requires during and after the provisioning process.
Examples of this I’ve seen include assigning a minimum number of site owners, assigning site owner training, applying site branding, adding the site to the global navigation, adding custom content types and metadata, etc.
How can site provisioning help with compliance? Depending on the maturity of an organization’s compliance program and the license you have available, there are varying compliance controls that could be included in the provisioning process:
- Retention Policies – publish retention policies to containers using Adaptive Scopes (coming soon) to include/exclude a site based on a site attribute or a user based on a user attribute. Without the additional license to use this feature, this has traditionally been done with custom code/PowerShell.
- Retention Label Policies – publish retention label(s) to containers using Adaptive scopes (coming soon) to include/exclude a site based on a site attribute or a user based on a user attribute. Without the additional license to use this feature, this has traditionally been done with custom code/PowerShell.
- Site sensitivity – apply a sensitivity label to the container being provisioned (Site, Team, Group) to control unmanaged device access, site privacy, external sharing, and guest access. Check out this post for How to Monitor Changes to Sensitivity Labels used for Container Management.
- Data Loss Prevention Policies – include the SharePoint site in a policy.

The Up-and-Comers
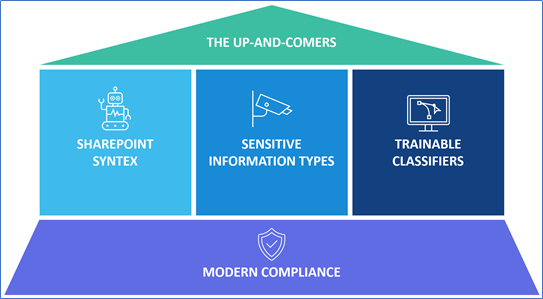
Although it’s important to understand how the world of SharePoint site and information architecture has changed for the modern workplace, and specifically compliance, it’s equally important to be aware of capabilities that can scale to help automate compliance using pattern matching, keyword dictionaries, artificial intelligence, and machine learning methods. With the abundance of SharePoint sites being created across tenants today (whether created as a standalone Team site, Communication site, thru a Microsoft Team, as a copied Planner plan, etc.), it’s nearly impossible for information architects to control the proliferation of content being produced across them like once might have been possible.
For this reason, we need to lean in on new classification and automation capabilities to help and to ensure we can apply compliance at scale across our entire tenant… even to sites and content we may not yet be aware of. Here are a few of the new features to become familiar with to enhance your options…
SharePoint Syntex
SharePoint Information Architects will be able to extend their knowledge of content types and metadata with SharePoint Syntex, a new, intelligent solution built using Azure Cognitive Services(Document Understanding model) and AI Builder(Form Processing model) to deliver information architecture and compliance automation for documents.
Syntex models are directly related to a SharePoint content type and, with configuration, can extract metadata out of a document without any end-user intervention. Like traditional information architecture benefits, when these models are applied to content, they can help improve search, enable organization within libraries, and automate business processes. An added benefit is their ability to automatically set a retention label as well.
There is a cost to SharePoint Syntex to be considered by organizations. At the time of this writing, the cost is $60USD per user per year. The benefit gained from streamlining business processes by automatically extracting content types and metadata with the added benefit of compliance needs to be weighed against the cost. If you don’t require content types and metadata to be extracted, a trainable classifier may be a more appropriate choice to apply compliance at scale – an option covered further down in this post.
Unsure about SharePoint Syntex? This blog post provides five practical uses for your organization.
Sensitive Information Types
Sensitive Information Types (SITs) are pattern-based classifiers used to identify content you deem sensitive across your environment (Learn about sensitive information types). These are defined at the tenant level in the Compliance Admin Center and can be used in many ways and across many locations in your environment, including SharePoint.
Although a document isn’t tagged with a SIT like a piece of metadata configured on a document library is, compliance actions can automatically be taken once a SIT is detected. Automated pattern matching is done against content within a document (chat, email, and OneDrive for Business as well) to detect the presence of a SIT.
There are many built-in, industry-specific, region-specific SIT definitions provided by Microsoft; however, you can also build your own. For example, if you have a specific customer # list, a list of sensitive keywords, or a unique format to indicate a product # in your environment, you can build a custom SIT to suit (Example: https://practical365.com/custom-sensitive-information-types/). Whether built-in or custom, you can use SITs to apply compliance controls at-scale across your environment regardless of where the content is, making this a truly powerful addition to the Compliance story.
There can still be many other reasons why you may want to ALSO apply content types and metadata to content containing SITs; however, for compliance, detection of SITs is an effective way to apply compliance at scale.
[As of May 2021] You can use SITs in these compliance solutions:
- Retention Labels
- Data Loss Prevention Policies
- Sensitivity Labels (both client-side and service-side)
- Communication Compliance
Trainable Classifiers
Another way of identifying content and managing compliance at scale across your environment is with trainable classifiers. Unlike SharePoint Syntex, a trainable classifier does not tag content using traditional information architect techniques of content types and metadata values. Instead, you define classifiers in the Compliance Center by providing matching content samples in a training session. Once trained, the classifiers can be used to detect matching content across your tenant and then used in compliance solutions across many workloads in Microsoft 365, not just SharePoint.
Some great document use-cases for trainable classifiers are:
- Legal form documents
- Product pricing quotes
- Work orders
- Annual Financial reports
[As of May 2021] You can use Trainable Classifiers in these compliance solutions:
- Auto-apply a retention label based on detection of a trainable classifier
- Auto-apply a sensitivity label based on detection of a trainable classifier
- Communication Compliance
Note: Detection of a SIT or a trainable classifier will not assign a content type or metadata to content. To do this, you would need to choose a different option:
- SharePoint Syntex (either a Document Understanding or Form Processing model)
- Default a content type on a library
- Have an end-user manually select it
Closing Thoughts
I hope this post delivers the message that even the long-standing discipline of SharePoint site and information architecture has had to change to be effective in today’s modern workplace. Therefore, it’s imperative that information architecture and information management/compliance teams are fully aligned on their approach to managing compliance effectively across all of SharePoint.


